Hello,
when I call loss.backward() I face the following problem:
RuntimeError: element 0 of tensors does not require grad and does not have a grad_fn
In my project (cloned from GitHub - geomagical/lama-with-refiner: 🦙 LaMa Image Inpainting, Resolution-robust Large Mask Inpainting with Fourier Convolutions, WACV 2022), I want to optimize an intermediate feature map while all network parameters remain unchanged (my network is pretrained).
This is my _infere function:
masked_image = image * (1 - mask)
masked_image = torch.cat([masked_image, mask], dim=1)
mask = mask.repeat(1, 3, 1, 1)
if ref_lower_res is not None:
ref_lower_res = ref_lower_res.detach()
with torch.no_grad():
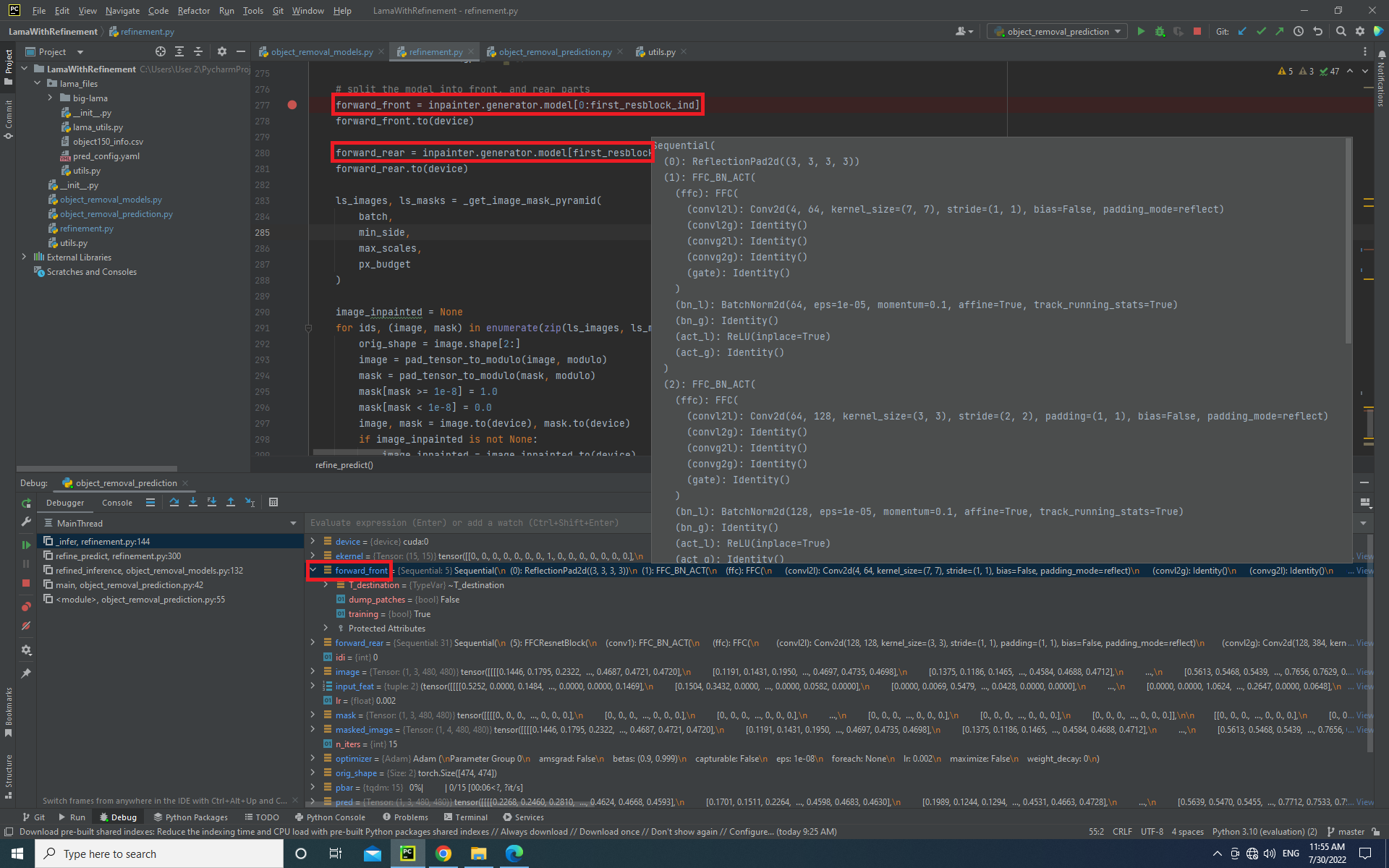
z1, z2 = forward_front(masked_image)
# Inference
mask = mask.to(device)
ekernel = torch.from_numpy(cv2.getStructuringElement(cv2.MORPH_ELLIPSE, (15, 15)).astype(bool)).float()
ekernel = ekernel.to(device)
image = image.to(device)
z1, z2 = z1.detach().to(device), z2.detach().to(device)
z1.requires_grad, z2.requires_grad = True, True
loss_fn = nn.L1Loss(size_average=None, reduce=None, reduction='mean')
optimizer = Adam([z1, z2], lr=lr)
pbar = tqdm(range(n_iters), leave=False)
for idi in pbar:
optimizer.zero_grad()
input_feat =(z1, z2)
pred = forward_rear(input_feat)
if ref_lower_res is None:
break
# losses = {}
# ------------------------- multi-scale -------------------------
# scaled loss with downsampler
pred_downscaled = _pyrdown(pred[:, :, :orig_shape[0], :orig_shape[1]])
mask_downscaled = _pyrdown_mask(mask[:, :1, :orig_shape[0], :orig_shape[1]], blur_mask=False, round_up=False)
mask_downscaled = _erode_mask(mask_downscaled, ekernel=ekernel)
mask_downscaled = mask_downscaled.repeat(1, 3, 1, 1)
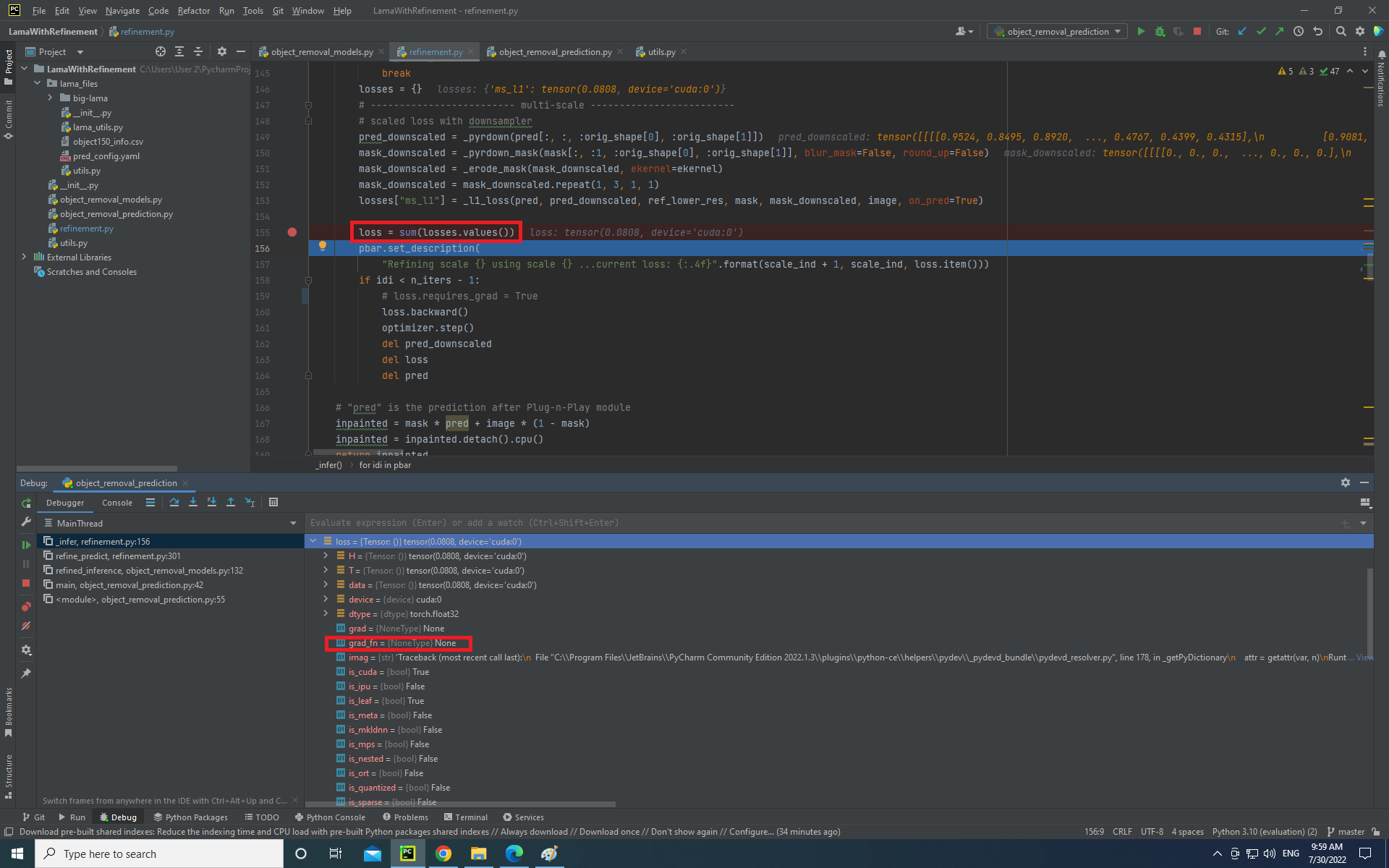
loss = loss_fn(pred[mask < 1e-8], image[mask < 1e-8]) + \
loss_fn(pred_downscaled[mask_downscaled >= 1e-8], ref_lower_res[mask_downscaled >= 1e-8])
pbar.set_description(
"Refining scale {} using scale {} ...current loss: {:.4f}".format(scale_ind + 1, scale_ind, loss.item()))
if idi < n_iters - 1:
loss.backward()
optimizer.step() # to optimize z
del pred_downscaled
del loss
del pred
# "pred" is the prediction after Plug-n-Play module
inpainted = mask * pred + image * (1 - mask)
inpainted = inpainted.detach().cpu()
return inpainted
when I write loss.requires_grad = True before loss.backward, loss remains constant. I have checked other topics, but none of them were helpful.
What is the problem?
As I’ve noticed loss.backward calculates the gradient of all parameters for which we set required_grad= True. So is there any way to check which parameters have required_grad= True?