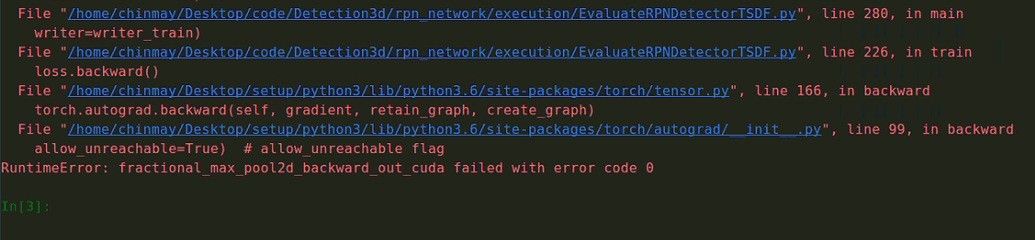
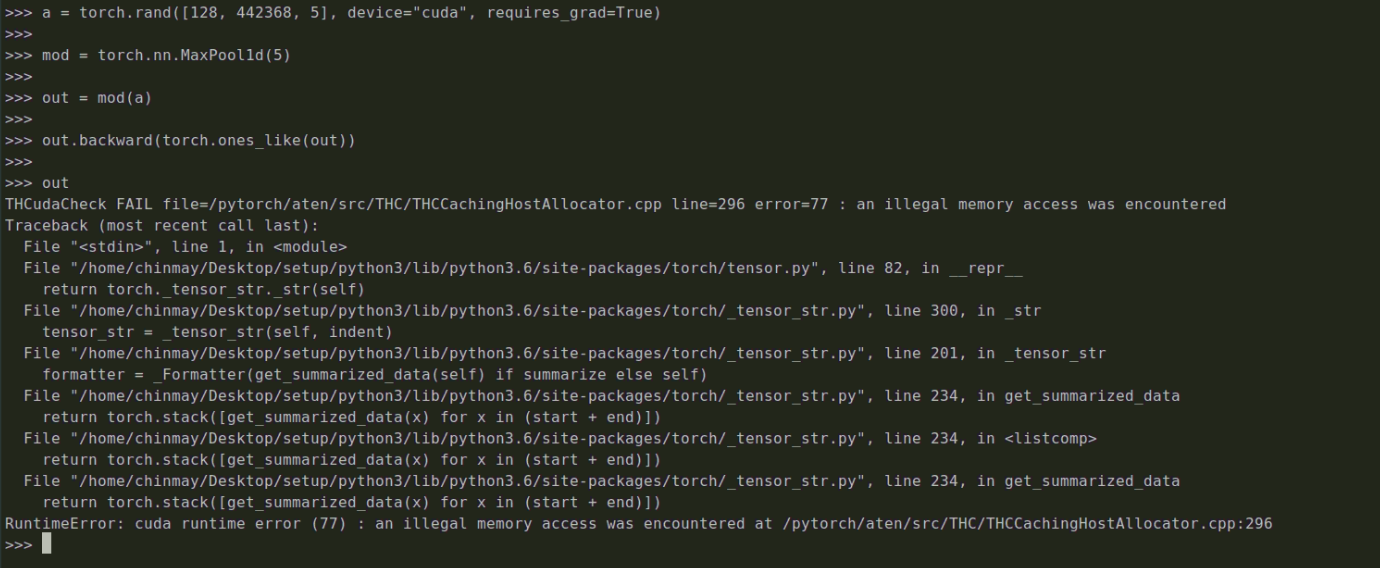
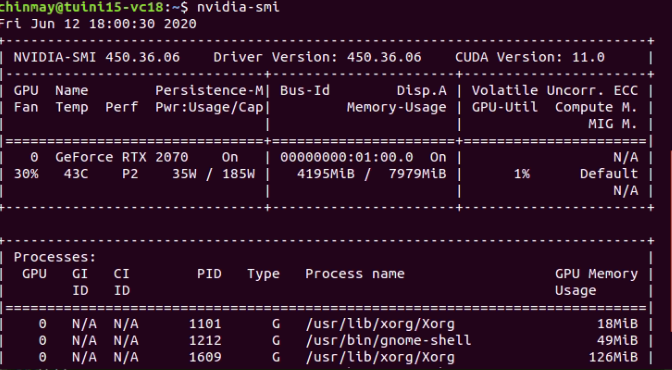
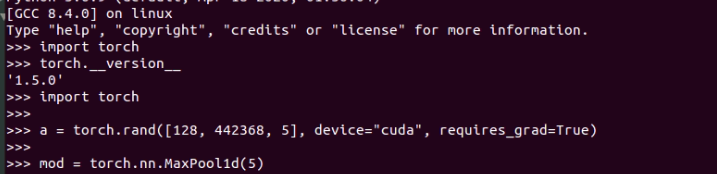
Sorry that I am asking this again but I would need a confirmation before I try to switch to the nightly builds for the issue since they seem to be a bit unstable.
You can try to enable torch.autograd.set_detect_anomaly(True) to see which forward function corresponds to the failing one in the backward.
Also You can try to run the same code on CPU to see if you get a better error message.
Also, I would double check all the indices in the multiple indexing you do.
Finally. You should never use .data anymore. This will reduce the chance of weird bugs a lot
For the .data, it depends what you use it for.
If you want to get a new tensor detached from the previous one wrt to the autograd, use .detach().
If you want to do ops that are not tracked by the autograd inplace, use the context manager with torch.no_grad().
Also for the .data as you can see here, I am taking the gradients, reshaping it and doing a mask select. I am sorry but I am not sure to which of the mentioned categories would this fall to?
If you have no reason to use it, you can just remove it.
It used to be useful when working with Variables. But now that they don’t exist, you can just remove the .data
@albanD
I have not switched to nightly builds yet. I am using PyTorch 1.2 although I tried updating uptil 1.5 and error persists. In all the cases, I ended up using pip instllations.
As for the OS, it is Ubuntu 18.04 and the Cuda version is
I made a mistake. I was able to run the code snippet without error on the nightly build. I will try to see if it works on the entire code next and will update you asap
@albanD it works with the nightly version. Thank you so so much for all your support. I am pretty sure I could not have figured it out without your help