Problem
Recently, I have tried to use DDP. I just followed the tutorial to change my original code for DP.
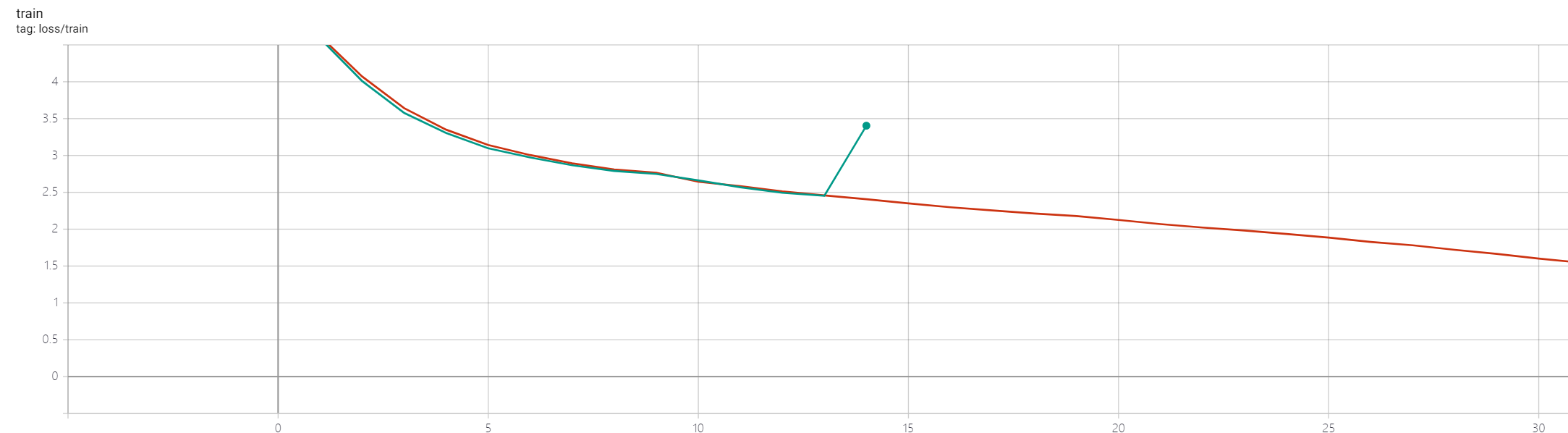
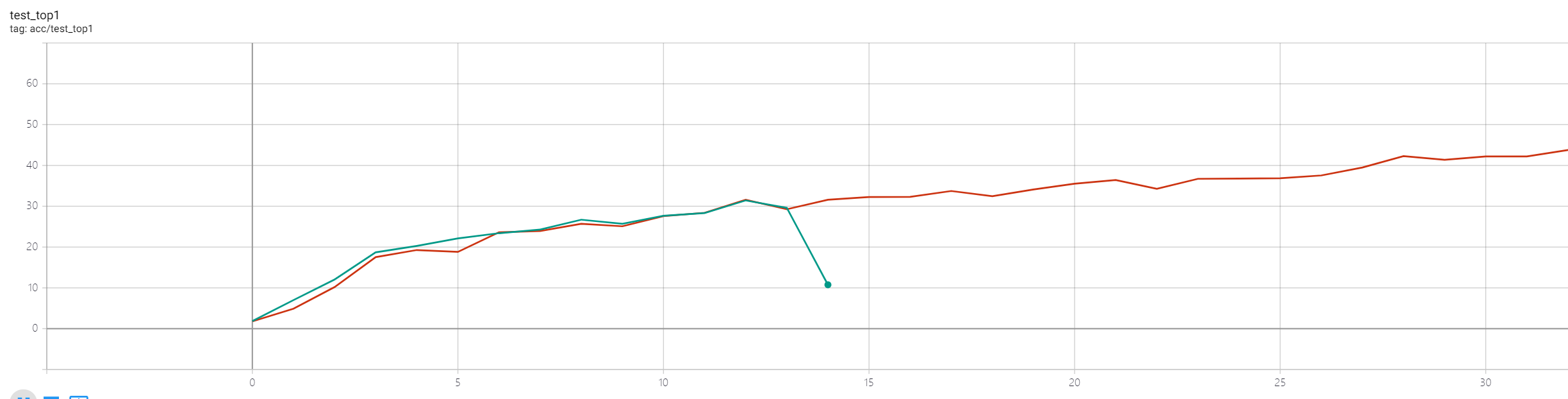
I accidentally stopped my DDP training, so I planned to resume model as what I did before. However, loss becomes much higher after resuming, I think it might be some error in my code.
Here are my codes
save model
# code for resuming after validation
if args.local_rank == 0:
tf_writer.add_scalar('acc/test_top1_best', best_prec1, epoch)
output_best = 'Best Prec@1: %.3f\n' % (best_prec1)
print(output_best)
log_training.write(output_best + '\n')
log_training.flush()
save_checkpoint({
'epoch': epoch + 1,
'arch': args.arch,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
'best_prec1': best_prec1,
}, is_best)
def save_checkpoint(state, is_best):
filename = '%s/%s/ckpt.pth.tar' % (args.root_model, args.store_name)
torch.save(state, filename)
if is_best:
shutil.copyfile(filename, filename.replace('pth.tar', 'best.pth.tar'))
I don’t save scheduler because I manually set the learning rate for the optimizer. And I will set learning rate before training.
adjust_learning_rate(optimizer, epoch, args.lr_type, args.lr_steps)
resume model
if args.resume:
if os.path.isfile(args.resume):
checkpoint = torch.load(args.resume, map_location=torch.device('cpu'))
pretrained_dict = checkpoint['state_dict']
new_state_dict = OrderedDict()
for k, v in pretrained_dict.items():
if '.total' not in k:
name = k[7:] # remove 'module.'
# name = name.replace('.net', '')
new_state_dict[name] = v
model.load_state_dict(new_state_dict)
model=torch.nn.parallel.DistributedDataParallel(model,
device_ids=[local_rank],
output_device=local_rank)
if 'epoch' in checkpoint.keys():
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
# get_optim_policies is a fuction to set optimizer policies
optimizer = torch.optim.SGD(get_optim_policies(model), lr=args.lr, momentum=args.momentum, weight_decay=args.weight_decay)
optimizer.load_state_dict(checkpoint['optimizer'])
print(("=> loaded checkpoint '{}' (epoch {})"
.format(args.evaluate, checkpoint['epoch'])))
print(("=> best top1 '{}'".format(best_prec1)))
The above codes work well when I use DP. Are there anything I miss while using DDP?