I am using Coco Dataset’s pictures and mask image that I crreated with the below script to do sematic segmentation.
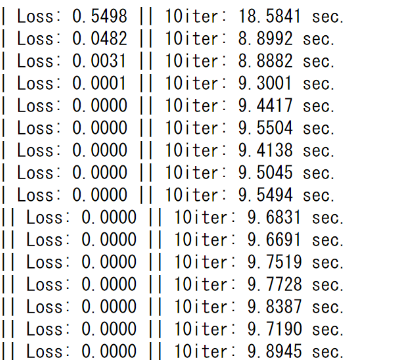
Why is my cross entropy loss function returning zero after a few dozen pictures?
def make_palatte (classes):
plt_dict = {0: ["backgorund", (0,0,0)]}
all_colors_map = []
palette = []
for i in range(255):
for ii in range(255):
for iii in range(255):
adding = [i, ii, iii]
if adding ==[0,0,0] or adding == [255, 255, 255]:
pass # ["backgorund", (0,0,0)]
all_colors_map.append(adding)
distance = len(all_colors_map)/(len(classes)+10) # buffer
distance = math.floor(distance)
for one_class in classes:
#print(one_class)
id = one_class["id"] #starts with 1
name = one_class["name"] # word
color = all_colors_map[int(id)*distance]
palette.extend(color)
plt_dict[id] = [name, tuple(color)]
# 1 already taken by background
palette.extend([255,255,255])
plt_dict[len(plt_dict)+2] =["ambiguous", (255,255,255)]
return plt_dict, palette
def mask_maker (palette_dict, img_id, height, width, palette, segmentation, export_dir):
im = Image.new("P", (height, width), color=(0,0,0)) # 0 0 0 >> background
im.putpalette(palette)
d = ImageDraw.Draw(im)
if len(segmentation) == 0:
im.save(export_dir)
return
for segment in segmentation: #a["segmentation"] = xy coordinates
#print(segment["segmentation"])
xy_tup_list = []
category_id = int(segment["category_id"])
if len(segment["segmentation"]) == 0:
im.save(export_dir)
return
for idx, point in enumerate(segment["segmentation"][0]):
if idx % 2 == 0: #STARTS WITH 0
x = point
if idx % 2 !=0:
y = point
xy_tup_list.append((x, y))
x = None
y = None
d.polygon(xy_tup_list, fill=category_id)
#d.polygon(xy, fill=category_id)
im.save(export_dir)
I randomly picked 1000train pictures and 600 val from COCO 2014 dataset excluding ones that have iscrowd=1. I am trying to do semantic segmentation on those 90 coco classes+ background.
I am using Pyramid Scenen Parsing Network which I pretty much copied from here except for the dataloader. pytorch_advanced/3_semantic_segmentation/3-7_PSPNet_training.ipynb at master · YutaroOgawa/pytorch_advanced · GitHub.
This original model did fine tuning with VOC pascal dataset. but i am trying to use COCO datset instead.
To create the mask, I basically drew polygon with PIL’s drawimage and assigned value by using “P” mode and original color pallet that has 90 colors and corresponding numbers.
below is my train function
def train_model(net, dataloaders_dict, criterion, scheduler, optimizer, num_epochs):
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print("available:", device)
net.to(device)
torch.backends.cudnn.benchmark = True
num_train_imgs = len(dataloaders_dict["train"].dataset)
num_val_imgs = len(dataloaders_dict["val"].dataset)
batch_size = dataloaders_dict["train"].batch_size
iteration = 1
logs = []
# multiple minibatch
batch_multiplier = 3
for epoch in range(num_epochs):
t_epoch_start = time.time()
t_iter_start = time.time()
epoch_train_loss = 0.0
epoch_val_loss = 0.0
print('-------------')
print('Epoch {}/{}'.format(epoch+1, num_epochs))
print('-------------')
for phase in ['train', 'val']:
if phase == 'train':
net.train()
scheduler.step()
optimizer.zero_grad()
print('(train)')
else:
if((epoch+1) % 5 == 0):
net.eval()
print('-------------')
print('(val)')
else:
continue
count = 0 # multiple minibatch
for imges, anno_class_imges in dataloaders_dict[phase]:
if imges.size()[0] == 1:
continue
imges = imges.to(device)
anno_class_imges = torch.squeeze(anno_class_imges)
anno_class_imges = anno_class_imges.to(device)
# multiple minibatch
if (phase == 'train') and (count == 0):
optimizer.step()
optimizer.zero_grad()
count = batch_multiplier
with torch.set_grad_enabled(phase == 'train'):
outputs = net(imges)
loss = criterion(
outputs, anno_class_imges.long()) / batch_multiplier
print("loss: " loss)
#
if phase == 'train':
loss.backward() #
count -= 1 # multiple minibatch
if (iteration % 10 == 0):
t_iter_finish = time.time()
duration = t_iter_finish - t_iter_start
print('iteration {} || Loss: {:.4f} || 10iter: {:.4f} sec.'.format(
iteration, loss.item()/batch_size*batch_multiplier, duration))
t_iter_start = time.time()
epoch_train_loss += loss.item() * batch_multiplier
iteration += 1
else:
epoch_val_loss += loss.item() * batch_multiplier
t_epoch_finish = time.time()
print('-------------')
print('epoch {} || Epoch_TRAIN_Loss:{:.4f} ||Epoch_VAL_Loss:{:.4f}'.format(
epoch+1, epoch_train_loss/num_train_imgs, epoch_val_loss/num_val_imgs))
print('timer: {:.4f} sec.'.format(t_epoch_finish - t_epoch_start))
t_epoch_start = time.time()
log_epoch = {'epoch': epoch+1, 'train_loss': epoch_train_loss /
num_train_imgs, 'val_loss': epoch_val_loss/num_val_imgs}
logs.append(log_epoch)
df = pd.DataFrame(logs)
df.to_csv("log_output.csv")
torch.save(net.state_dict(), 'weights/pspnet50_' +
str(epoch+1) + '.pth')
num_epochs = 30
torch.cuda.empty_cache()
train_model(net, dataloaders_dict, criterion, scheduler, optimizer, num_epochs=num_epochs)

