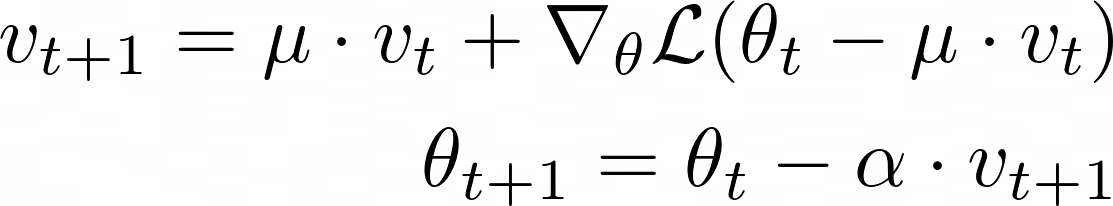According to this formula, the loss function should be calculated not according to our model’s parameters, but with a prediction of the future model’s parameters.
And using a torch SGD optimizer with Nesterov should look like the following:
My question is how can optimizer.step() apply the correct parameter update (in the Nesterov case) if the loss is calculated according to the model’s present parameters and not “future” parameter predictions as in the equation above? I already looked at the source code and I still do not understand how this was done.
Does PyTorch call the forward method of the model and somehow overwrites its parameters in model(input)? If that is the case, how is that done?
I am not 100% sure but I think the trick is to have the parameters actually contain \theta_t - \mu v_t. That way a regular forward/backawrd evaluates the right value and you only need to update the step formula to take this into account.
I guess it does make some sense that way, but those parameters would have to be changed before the model(input) instruction, or while that instruction is being evaluated, I guess.
Also not sure if the parameters should not be reverted back before calling backward(), though, would that not have an impact on the gradient calculation?