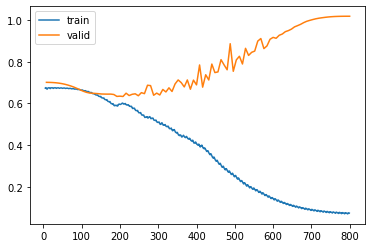
Trying to ask this in a fairly architecture agnostic way. Here is my loss plot for a single-label two-class binary cross entropy problem:
My interpretation is that I’m overfitting fairly badly. But, overfitting is my goal for the moment. My expectation is that if I were to apply this model to the training data, the model’s predictions should look good, since it has memorized the training data. However, I am not actually seeing this; instead, my model performs terribly on training data, which is surprising.
Am I right to be surprised that my model is performing badly on the very training data that it appears to be overfit to?
That is an interesting insight. Is your thought that this mixup is only happening in my training loop, so that the labels are mixed up but fixed and therefore learnable (explaining the improvement in loss during training)? And then when I am no longer in the training loop, I evaluate the model in a way where the labels are not mixed up, which is why the results don’t hold up?
I think there’s something wrong with labels during training loop because BCELoss = -ln(1-x) if label==0 and -ln(x) if label==1. It can decrease only if your predictions are getting closer to labels you provided.
If bce loss is dropping to .1 it means average distance between labels and predictions is about 0.095 (solve -ln(x)=.1 for label==1 or -ln(1-x)=.1 for label==0)
After following up on your suggestion to investigate the training loop, I think I narrowed down the issue to a mal-alignment between X and Y in my dataloader. I’m still not 100% sure of the root cause, but it seems to be due to an error in my mental model of when pandas may reorder data. When I manually join X and Y before converting them to tensors, I can overfit as expected (same appearance as the above plot) but reassuringly I can also reproduce the overfit values outside of the training loop.