Hello,
I’m having some trouble getting my system to train even when using the simplest of examples. To demonstrate my issue I have created a quick toy problem a two layer NN which should calculate the output of the XOR function. However, my loss never seems to decrease.
import torch
import torch.nn as nn
import numpy as np
import random
dataset = [ [1,1], [1,0], [0,1], [0,0] ]
labelset = [ [0], [1], [1], [0] ]
class Model(nn.Module):
def __init__(self):
super().__init__()
self.lin = nn.Sequential(
nn.Linear(2,2),
nn.Linear(2,2)
)
#self.lin = nn.Linear(2,2)
def forward(self, inp):
return self.lin(inp)
net = Model()
net.train()
# define loss function
criterion = torch.nn.CrossEntropyLoss()
# define optimizer
params = list(net.parameters())
optimizer = torch.optim.SGD(params, 0.1)
# Train Network
#----------------
losses = []
epoch = 200
with torch.autograd.detect_anomaly():
for e in range(epoch):
i = random.randint(0, 3)
data = torch.tensor([dataset[i]], dtype=torch.float)
label = torch.tensor(labelset[i])
data = torch.autograd.Variable(data)
label = torch.autograd.Variable(label)
# compute output
logits = net(data)
# get loss
loss = criterion(logits, label)
loss.backward()
# optimize SGD
optimizer.step()
optimizer.zero_grad()
losses.append(loss.cpu().detach().numpy())
# show Losses
import matplotlib
import matplotlib.pyplot as plt
plt.plot(losses)
plt.savefig("analysis/fig/plt.png")
# eval model
net.eval()
with torch.no_grad():
for i in range(len(dataset)):
data = torch.tensor([dataset[i]], dtype=torch.float)
label = labelset[i]
data = torch.autograd.Variable(data)
logits = net(data)
out = np.argmax(logits.cpu().detach().numpy())
print(dataset[i], out, label)
Here is the loss over the course of the run (loss is on the y axis and epoch is on the x axis):
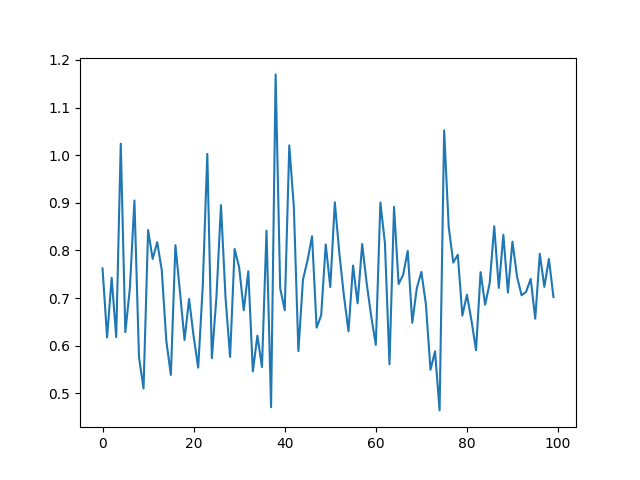
I presume that I have missed some pivotal step in the code or messed up some value in the hyper-parameters but I can’t for the life of me figure out what it is. Any help would be appreciated. Thank you
