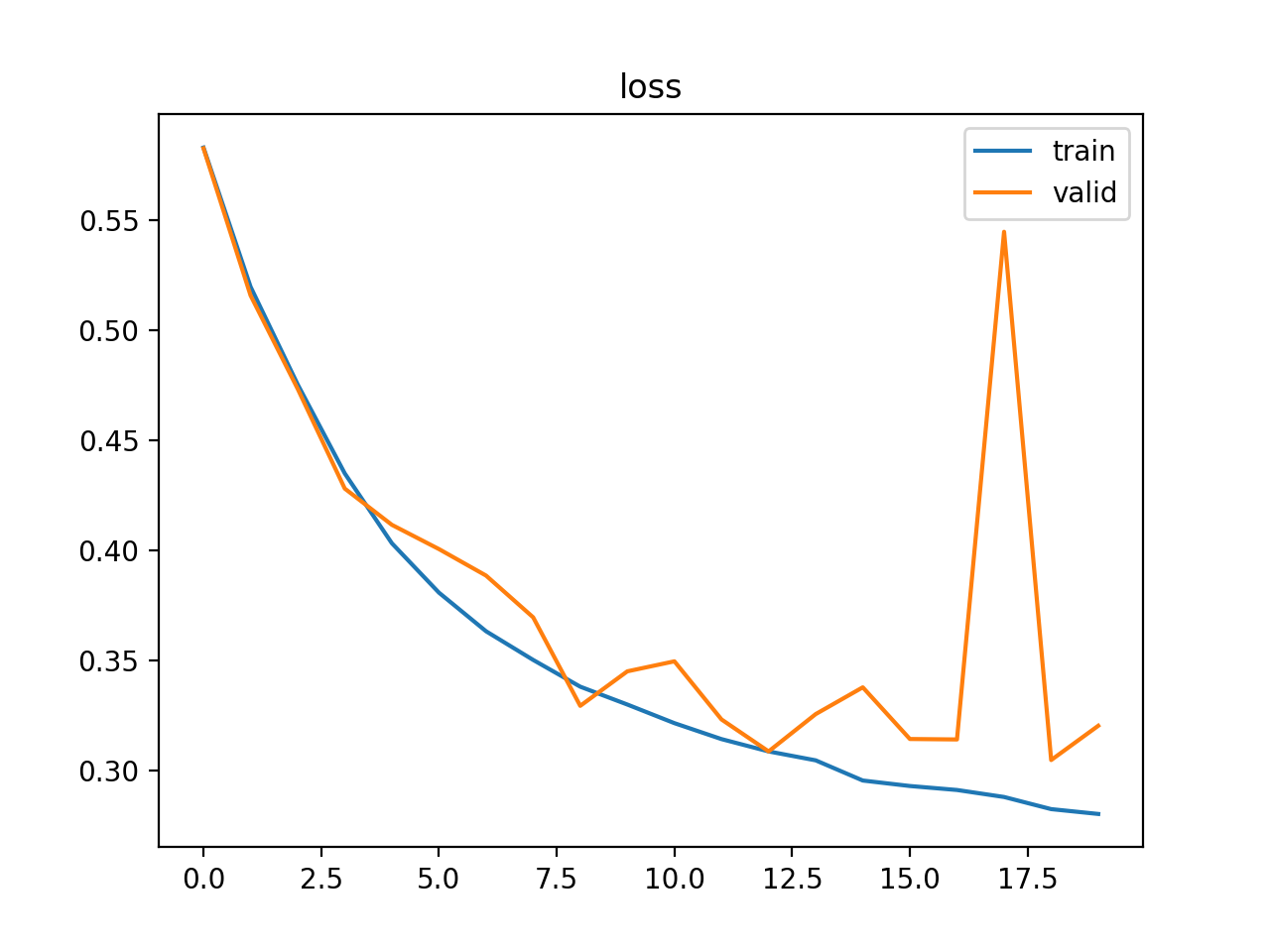
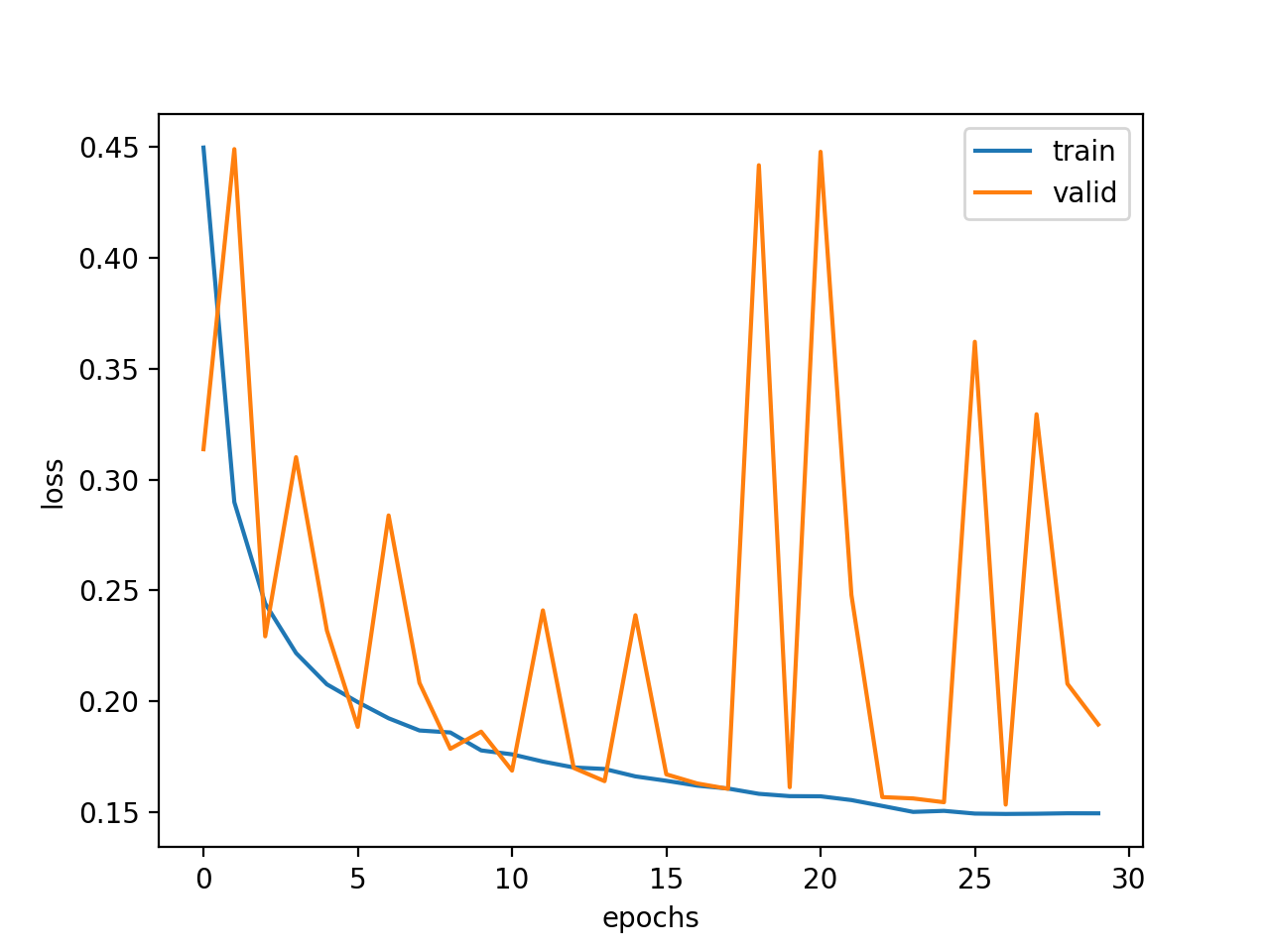
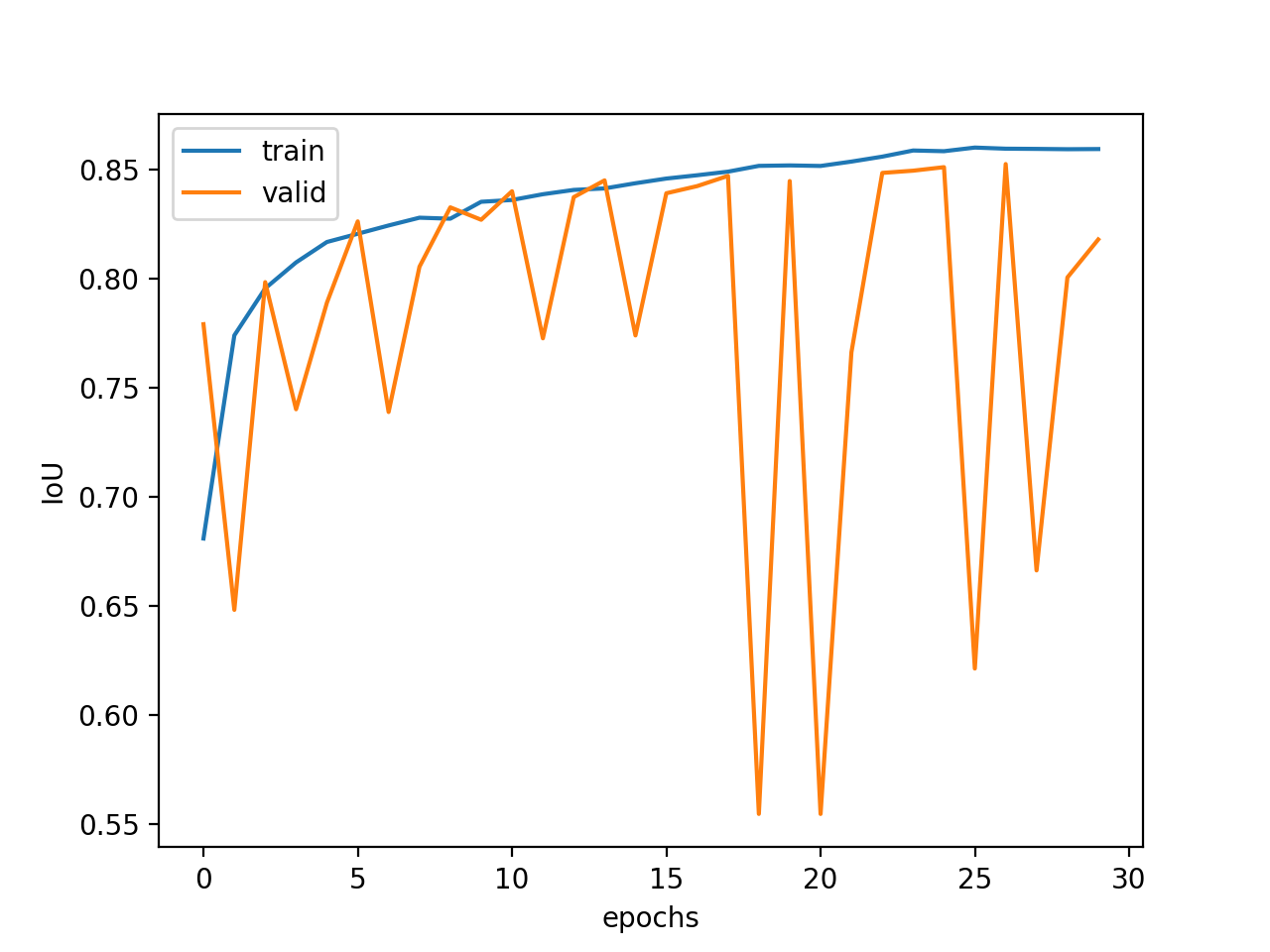
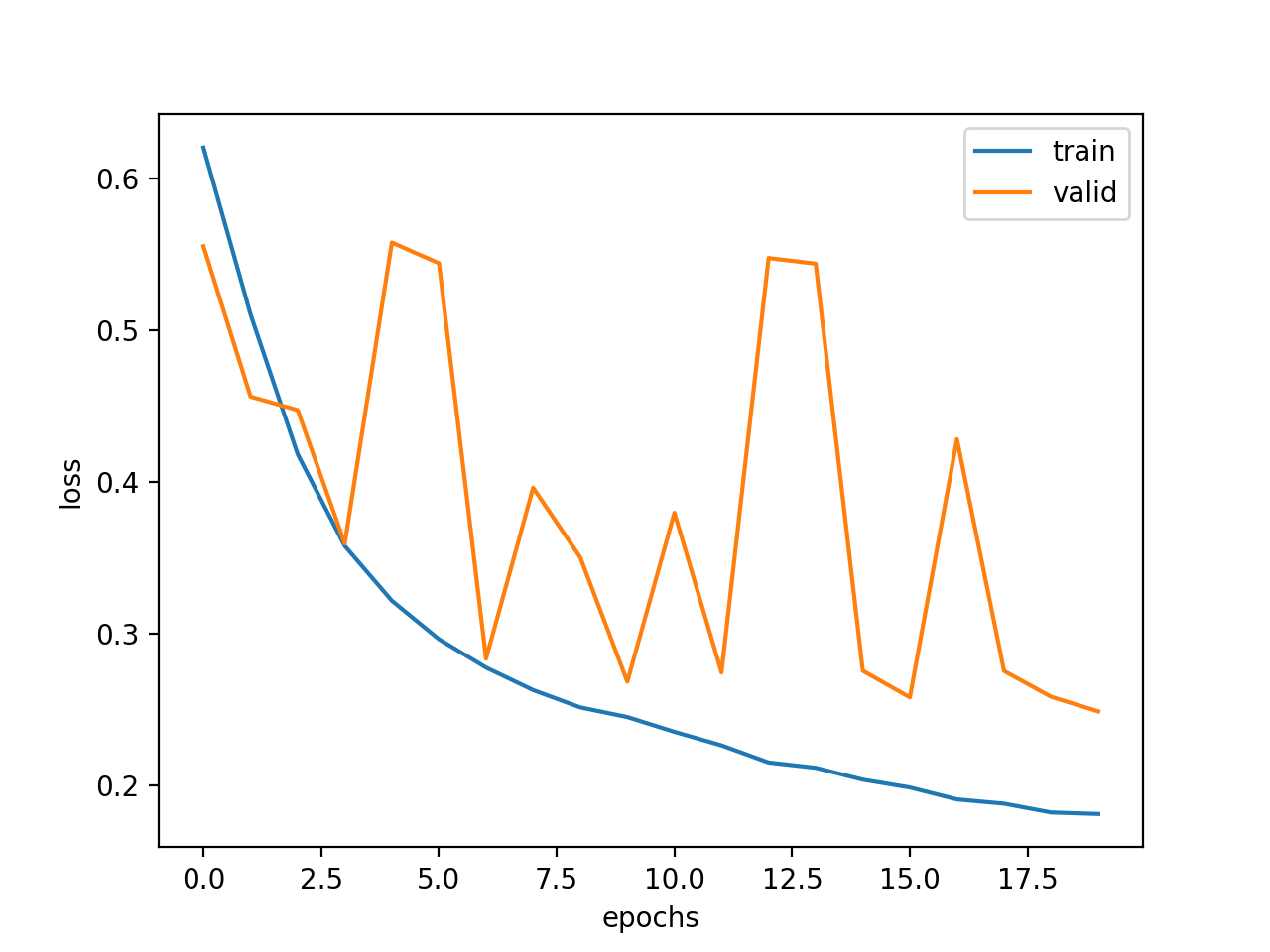
For semantic segmentation I trained a network using a learning rate of 5*10**-4, mini-batchsize 2 and a Momentum of 0.8 with image size 256x384. The only custom transformation applied is a center crop. The loss after 20 Epochs looks like the following:
Indeed, it is quite odd. My guess is that it will require a deep debug. BTW, did you check that the train and validation data-sets have the same distribution ?
Otherwise, I’d pick two consecutive checkpoints: a good and a bad. Then, I’d pick a sample were both predict good results and a sample where only the good predicts the good results. Then, I’d look at the last activations, and see the differences. It may take a lot of time, and maybe the solution wouldn’t be straightforward.
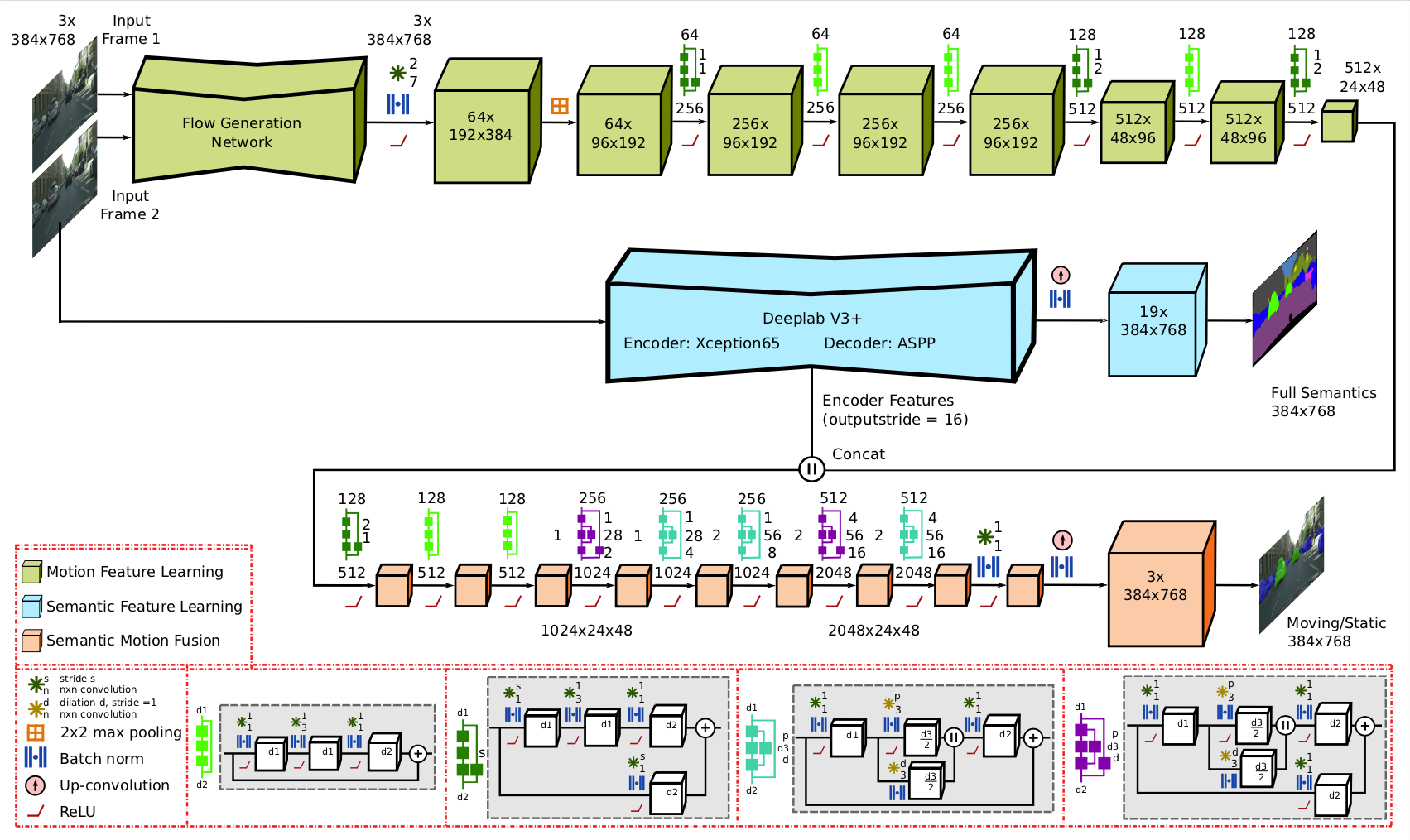
Im using a semantic segmentation network, which is also incorporating the motion state to differentiate between moving and static cars.
I used the cityscapes motion dataset [deepmotion], which provides 2975 training images and 500 validation images. Because I train only small images, I splitted the images in 3 overlapping frames, to get 3 times the amount of training images.
Yes the network behave totally different in train() and valid() mode. Is there a reason for it ? I used some dropout layers.
Im preprocessing the optical flow with FlowGenerationNetwork (PWCNet) and the segmentation features (with Deeplab) and inputting it in the final network, for calculating the Lovasz loss.
I also switched some training images with the validation set and trained it. It gave me more or less the same results.
Thats a good idea. I have already plotted some results with high loss. Usually the prediction is biased towards the biggest class, which is the background. (I have just 3 classes: moving car, static car and background, see illustration from [DeepMotion])
Ok, 500 images is large enough of a validation set to not produce those big fluctuations. People sometimes leave the model in train() mode during evaluation and a batch size of 1, so the batch norm layers aren’t happy. I don’t think I can offer any insightful help, sorry. Good luck
I imagine you are using Cross-Entropy loss somewhere. You could try to balance the class importance on the loss by setting different weights. Maybe this thread could help a bit.
When I was using the cross-entropy loss, it was even more fluctuating. This is why Iam using the Lovasz loss, which is taking the IoU (L = 1 - IoUc). [Lovasz Softmax Paper] [Lovasz Overview Slide]
Should I also balance the classes for the Lovasz loss function ?
In training mode I use a batch size of 12 and in evaluation mode I use a batch size of 1. Is this a problem? But im always calculating the mean of the whole validation epoch for plotting the epochs.
One more question, when I want to further train the pertained model with an even smaller dataset with 700 images in the training dataset and 500 images in the validation. Is better to choose a really small learning rate in comparison to the first training?
Are you using any data augmentation? If you do, turn off all augmentation schemes, and train exclusively on natural images. Goal is to make sure there is nothing wrong with the data augmentation script.
Also, visualize the images in your batch (input and output): to make sure that the images that are fed to the model are consistent with what you expect.
I have experienced similar “noisy” validation loss, and it originated either from a bug in the data augmentation, or in the batch generator.
Sorry for the stupid question, maybe you have also already solved it, but are you really sure you are averaging the validation for all 500 images every epoch?
Your training loss should be way noisier than a mean of all validation images.
Unless there is a problem on your Lovasz loss…
Have you tried to optimize a smoothed IoU or DICE loss instead?