I’ve been working on an LSTM that performs sequence segmentation, where at each time step in the sequence my network labels the time step with one of 3 classes. I’ve recently been trying to overfit my network to a small dataset of 10 samples to validate that my network works. What’s been bothering me is that on some runs of my training notebook the loss decreases as expected, while on others it seems not to update at all:
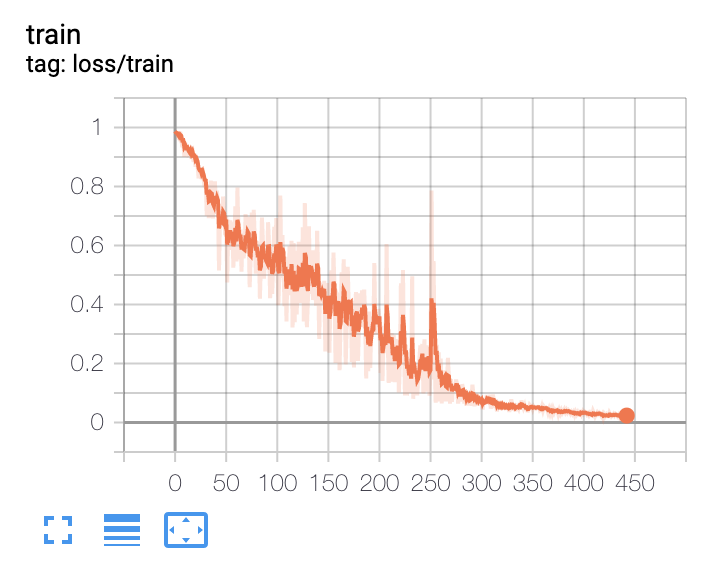
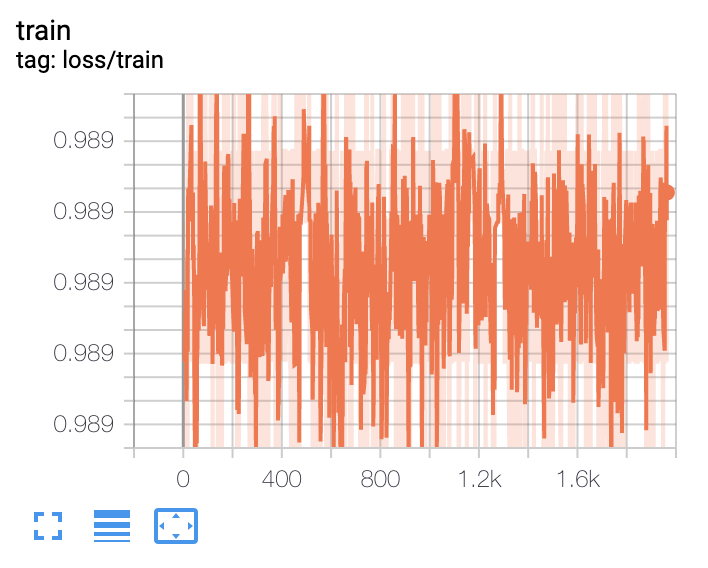
I can’t tell if this is due to an error in my training notebook/model/dataloader, or if this is just a result of some initializations of my network leading to very flat regions of the loss function. I’ve tried decreasing the model size from ~500k parameters down to ~30k parameters, and I’ve also modified the learning rate from 0.001 up to 0.1, but at each setting there are still occasions when the network fails to have the loss decrease. If anyone has run into a similar issue before, or sees an obvious problem with my code, I’d greatly appreciate a second opinion.
Network:
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
# definitions
NUM_CLASSES = 3
class MyLSTM(nn.Module):
def __init__(self, batch_size: int, input_size: int, hidden_size: int, num_layers: int, dropout: float, bidirectional: bool) -> None:
super(MyLSTM, self).__init__()
# state variables used by encoder to parse output of lstm
self.hidden_size = hidden_size
self.num_directions = (2 if bidirectional else 1)
# lstm to pass inputs through and update hidden states
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True, dropout=dropout, bidirectional=bidirectional)
# these kernel sizes, strides, and paddings have been fine tuned to get an output of size
# (batch_size x seq_len x NUM_CLASSES) to pass into our softmax for a hidden_size = 32
self.conv1 = nn.Conv2d(2, 1, kernel_size=(1, 2), stride=(1, 2))
self.conv2 = nn.Conv2d(1, 1, kernel_size=(1, 2), stride=(1, 2))
self.pool1 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 2))
self.pool2 = nn.MaxPool2d(kernel_size=(1, 2), stride=(1, 1))
def encoder(self, input_arr: torch.Tensor, lengths: torch.Tensor):
"""
Input array of dimensionality (batch_size x seq_len x input_size). Input array is sorted in
descending order of sequence length.
"""
# pack our zero-padded sequences
packed_seq = nn.utils.rnn.pack_padded_sequence(input_arr, lengths, batch_first=True)
# pass input through lstm
packed_output, _ = self.lstm(packed_seq)
# unpack the output which is (batch x seq_len x num_directions * hidden_size)
total_length = input_arr.size(1)
output, _ = torch.nn.utils.rnn.pad_packed_sequence(packed_output, batch_first=True, total_length=total_length)
# reshape output to separate forward and backward outputs; push forward/backward channels to dimension 1
batch_size = input_arr.size(0)
output = output.view(batch_size, total_length, self.num_directions, self.hidden_size)
output = output.permute(0,2,1,3)
return output
def forward(self, input_arr: torch.Tensor, lengths: torch.Tensor):
encoder_output = self.encoder(input_arr, lengths)
# pass outputs through convolution layers; output is (batch_size x seq_len x NUM_CLASSES)
conv_out1 = F.relu(self.pool1(self.conv1(encoder_output)))
conv_out2 = F.relu(self.pool2(self.conv2(conv_out1)))
conv_output = conv_out2.squeeze(1)
# pass output through softmax and permute to get (batch_size x NUM_CLASSES x seq_len)
return F.log_softmax(conv_output, dim=2).permute(0,2,1)
Training loop:
_, input_size = dataset_train[0]['vec'].shape
model = MyLSTM(batch_size=8, input_size=input_size, hidden_size=32, num_layers=2, dropout=0.5, bidirectional=True)
model.to(device)
LEARNING_RATE = 0.001
ALPHA = 0.9
LOG_ITERS = 10
SAVE_ITERS = 100
VAL_ITERS = 50
VAL_NUM_BATCHES = 10
n_iter = 0
def compute_sample_weight(num_labels):
labels_bincount_total = np.zeros(num_labels)
for sample in dataloader_train:
labels = sample['label_vec'].flatten()
labels = labels[labels >= 0]
labels_bincount_total += np.bincount(labels)
# rescale weights such that smallest weight is 1 and then invert weights
labels_bincount_total = labels_bincount_total/np.min(labels_bincount_total)
labels_bincount_total = 1/labels_bincount_total
return torch.from_numpy(labels_bincount_total).type(torch.float32)
nll_loss = nn.NLLLoss(weight=compute_sample_weight(num_labels=3)).to(device)
optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE)
EXP_NAME = "adam-train-only"
os.makedirs(f"logs/{EXP_NAME}", exist_ok=True)
os.makedirs(f"logs/{EXP_NAME}/weights/", exist_ok=True)
writer = SummaryWriter(f"logs/{EXP_NAME}")
for _ in range(1000):
for sample in dataloader_train:
if n_iter % 100 == 0:
print(f"At iteration: {n_iter}")
# zero parameter gradients
optimizer.zero_grad()
# load data
vecs = sample['vec']
label_vecs = sample['label_vec']
lengths = sample['length']
# sort in descending order of length
sorted_indices = np.argsort(-lengths)
sorted_vecs = vecs[sorted_indices].to(device)
sorted_label_vecs = label_vecs[sorted_indices].to(device)
sorted_lengths = lengths[sorted_indices].to(device)
preds = model(sorted_vecs, sorted_lengths)
_, preds_labels = torch.max(preds, dim=1)
loss = ALPHA*nll_loss(preds, sorted_label_vecs) # + BETA*my_loss
# compute accuracy - don't forget to remove padding values
preds_labels_arr = preds_labels.detach().cpu().numpy()
sorted_label_vecs_arr = sorted_label_vecs.detach().cpu().numpy()
good_indices = np.where(sorted_label_vecs_arr != -100)
preds_labels_arr = preds_labels_arr[good_indices]
sorted_label_vecs_arr = sorted_label_vecs_arr[good_indices]
accuracy = np.sum(preds_labels_arr == sorted_label_vecs_arr)/preds_labels_arr.size
# write training loss and accuracy
writer.add_scalar("loss/train", loss.item(), n_iter)
writer.add_scalar("accuracy/train", accuracy, n_iter)
# perform update
loss.backward()
optimizer.step()
# save model
if n_iter % SAVE_ITERS == 0:
torch.save(model.state_dict(), f"logs/{EXP_NAME}/weights/{n_iter}.pt")
n_iter += 1
I’d be happy to provide any clarifications or answer any questions.