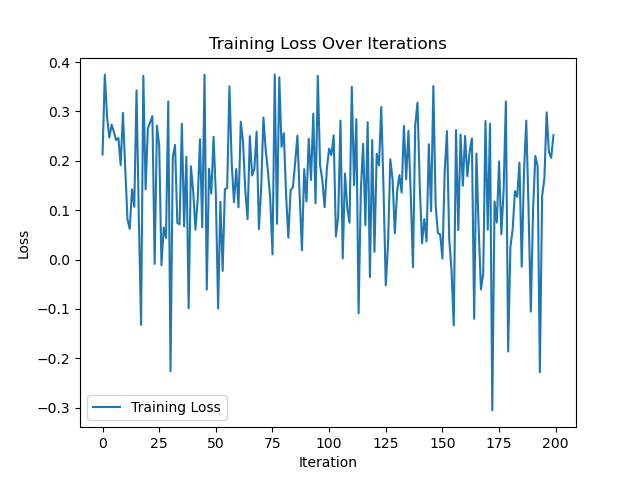
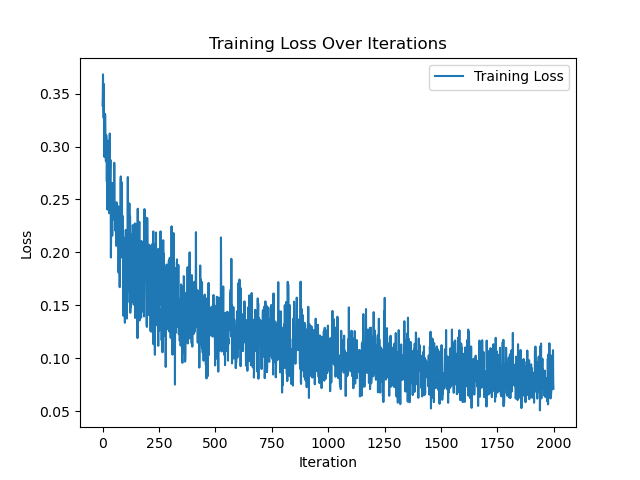
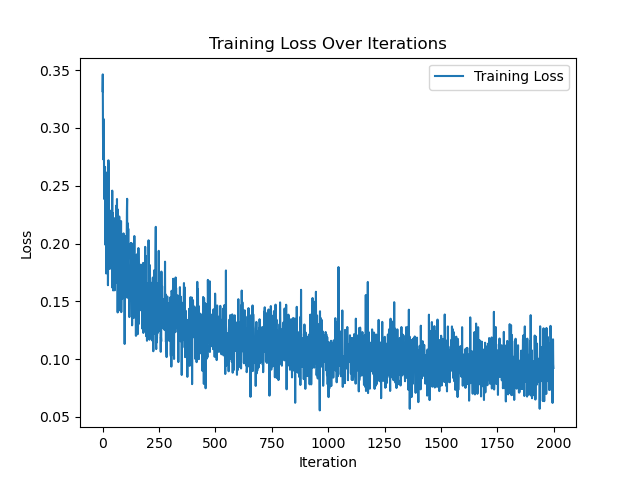
In my current code the loss is fluctuating - Currently, I’ve tried regularization, clipping, and changing the optimizer. Can you have a look at my code:
import tensorflow as tf
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
from utils import (get_elements_and_compositions_single_2,
method_six,
undo_method_six,
undo_method_six_2,
combine_elements_and_compositions)
from attention_bi_lstm_predict import predict_d_max
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import matplotlib.pyplot as plt
class Seq2Seq(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Seq2Seq, self).__init__()
self.hidden_size = hidden_size
# https://pytorch.org/docs/stable/generated/torch.nn.LSTM.html
self.encoder = nn.LSTM(input_size, hidden_size, batch_first=True)
self.decoder = nn.LSTM(hidden_size, hidden_size)
self.fc = nn.Linear(hidden_size, output_size)
def forward(self, input_seq):
_, (encoder_hidden, _) = self.encoder(input_seq)
decoder_output, _ = self.decoder(encoder_hidden)
output = self.fc(decoder_output)
output = F.softmax(output, dim=2)
output_lens = np.count_nonzero(np.count_nonzero(input_seq.numpy(), axis=2), axis=1)
output_masks = []
for output_len in output_lens:
output_mask = []
max_len = 10
for i in range(max_len):
if i < output_len:
output_mask.append(1)
else:
output_mask.append(0)
output_masks.append(output_mask)
output_masks = torch.FloatTensor(output_masks)
output = output.squeeze(0) * torch.FloatTensor(output_masks)
output_sum = output.sum(dim=1, keepdim=True)
output = output / output_sum
return output
def custom_loss(output, target, inputs):
# TODO: define the strategy of the loss here
distance = (output - target).pow(2).sum(1).sqrt()
output_np = output.detach().numpy()
target_np = target.detach().numpy()
elements_batch = undo_method_six_2(inputs.numpy())
reinforcement_reward = 0
better_performance_batch_count = 0
for i in range(len(elements_batch)):
generated_alloy = combine_elements_and_compositions(elements=elements_batch[i], compositions=output_np[i])
iteration_alloy = combine_elements_and_compositions(elements=elements_batch[i], compositions=target_np[i])
generated_d_max = predict_d_max(generated_alloy)
iteration_d_max = predict_d_max(iteration_alloy)
# print(f"generated: {generated_alloy} generated_d_max: {generated_d_max}")
# print(f"iteration: {iteration_alloy} iteration_d_max: {iteration_d_max}")
if generated_d_max > iteration_d_max:
better_performance_batch_count += 1
reinforcement_reward -= 0.1
with open("model_generated.txt", "a") as file:
# alloy, d_max, difference_in_d_max, n_elements
file.write("\n" + generated_alloy + "," + str(generated_d_max) + "," + str(generated_d_max - iteration_d_max) + "," + str(len(elements_batch[i])))
print(f"performed better: {better_performance_batch_count}")
return torch.mean(distance) + reinforcement_reward
if __name__ == "__main__":
df = pd.read_csv("best_compositions.csv")
X = []
y = []
for i in range(len(df)):
elements, compositions = get_elements_and_compositions_single_2(df.iloc[i]["best_bmg_alloy"])
vector = method_six(elements=elements)
compositions = np.array(compositions + [0] * (10 - len(compositions))) / 100.0
print(compositions)
X.append(vector)
y.append(compositions)
X = np.array(X)
y = np.array(y)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42, shuffle=True)
print("X_train shape: ", X_train.shape, "y_train shape: ", y_train.shape)
X_train = torch.tensor(torch.from_numpy(X_train).float())
y_train = torch.tensor(torch.from_numpy(y_train).float())
training_dataset = torch.utils.data.TensorDataset(X_train, y_train)
training_loader = torch.utils.data.DataLoader(training_dataset, batch_size=32, shuffle=True)
X_test = torch.tensor(torch.from_numpy(X_test).float())
y_test = torch.tensor(torch.from_numpy(y_test).float())
testing_dataset = torch.utils.data.TensorDataset(X_test, y_test)
testing_loader = torch.utils.data.DataLoader(testing_dataset, batch_size=1, shuffle=False)
model = Seq2Seq(input_size=200, output_size=10, hidden_size=128)
# optimizer = torch.optim.SGD(model.parameters(), lr=0.0001, momentum=0.9)
optimizer = torch.optim.Adam(model.parameters(), lr=1e-4, weight_decay=1e-5)
num_epochs = 200
print_every = 2
plot_every = 1
all_losses = []
for epoch in range(num_epochs):
for i, data in enumerate(training_loader):
# https://github.com/pytorch/pytorch/issues/309
inputs, labels = data
optimizer.zero_grad()
outputs = model(inputs)
loss = custom_loss(outputs, labels, inputs)
loss.backward()
clipping_value = 1
torch.nn.utils.clip_grad_norm_(model.parameters(), clipping_value)
optimizer.step()
if (epoch + 1) % print_every == 0 and i == len(training_loader) - 1:
print(f"Epoch [{epoch + 1}/{num_epochs}], Loss: {loss.item()}")
if (epoch + 1) % plot_every == 0 and i == len(training_loader) - 1:
all_losses.append(loss.item())
plt.plot(all_losses, label='Training Loss')
plt.title('Training Loss Over Iterations')
plt.xlabel('Iteration')
plt.ylabel('Loss')
plt.legend()
plt.savefig("model_loss.png")
torch.save(model.state_dict(), "bmg_generator.pt")
model.eval()
total_loss = 0.0
num_batches = 0
with torch.no_grad():
for i, data in enumerate(testing_loader):
inputs, labels = data
outputs = model(inputs)
elements = undo_method_six(inputs.numpy())
if len(elements) == 3:
output_np = outputs.detach().numpy()
target_np = labels.detach().numpy()
print(output_np)
generated_alloy = combine_elements_and_compositions(elements=elements, compositions=output_np[0][:len(elements)])
iteration_alloy = combine_elements_and_compositions(elements=elements, compositions=target_np[0][:len(elements)])
generated_d_max = predict_d_max(generated_alloy)
iteration_d_max = predict_d_max(iteration_alloy)
if generated_d_max > iteration_d_max:
print(generated_alloy + "\tFound a winner!")
else:
print("iteration wins:(")
loss = custom_loss(outputs, labels, inputs)
total_loss += loss.item()
num_batches += 1
average_loss = total_loss / num_batches
print(f"Test Loss: {average_loss}")