The problem is that of text classification where each document can be identified with one or more labels (104). So given a prediction \hat{y} of size (batch_size, 104) and a multi-one hot vector y of size (batch_size, 104) which consists of value 1 for the labels it contains and values 0 for the labels it does not contain, I would want a vector loss_labels of size (104, 1) where the value at position l in this vector is given by
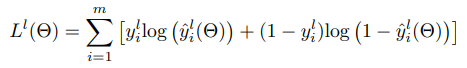
Here y_i^l is the true lth label of ith sample and \hat{y}_i^l is the same thing for the predicted output.
Hi Anshul!
You should use binary_cross_entropy_with_logits() with no
“reduction.” Thus:
torch.nn.functional.binary_cross_entropy_with_logits (prediction, loss_labels, reduction = 'none')
This will return a tensor of loss values of shape [batch_size, 104]
(neither summed, nor averaged, nor otherwise “reduced” over any of its
dimensions) that you can then sum over the batch dimension. (If you
really want the trailing singleton dimension, use unsqueeze().)
Note that binary_cross_entropy_with_logits() takes a prediction
consisting of raw-score logits, rather than the probabilities that would
be passed to binary_cross_entropy(). This is preferred for reasons
of numerical stability.
(You could also use BCEWithLogitsLoss if you prefer the class over the
function version.)
Best.
K. Frank
1 Like
Hi @KFrank,
Your clarification will be appreciated on a similar topic which you had answered in the past.