I am trying to train an autoencoder for a simple reconstruction task.
The aim of my AE is just to learn the raw input data as much as it can. That’s it.
class Encoder_layer(nn.Module):
def __init__(self, dropout: float = 0.2, sws: int, embedding_dim:int):
super(Encoder_layer,self).__init__()
# assert int(sws/16) > embedding_dim
self.sws = sws
self.encoder_layer = nn.Sequential(
nn.Linear(sws, int(sws/4)),
nn.ReLU(),
nn.Dropout(dropout),
nn.Linear(int(sws/4), int(sws/16)),
nn.Tanh(),
nn.Dropout(dropout),
nn.Linear(int(sws/16), embedding_dim)
)
def forward(self, x: Tensor):
assert x.size(1) == self.sws
return self.encoder_layer(x)
class Decoder_layer(nn.Module):
def __init__(self, dropout: float = 0.2, sws: int, embedding_dim:int):
super(Decoder_layer,self).__init__()
self.embedding_dim = embedding_dim
self.decoder_layer = nn.Sequential(
nn.Linear(embedding_dim, int(sws/16)),
nn.ReLU(),
nn.Linear(int(sws/16), int(sws/4)),
nn.Tanh(),
nn.Linear(int(sws/4), sws)
)
def forward(self, x: Tensor):
assert x.size(1) == self.embedding_dim
return self.decoder_layer(x)
class Autoencoder_layer(nn.Module):
def __init__(self,encoder, decoder):
super(Autoencoder_layer, self).__init__()
self.encoder = encoder
self.decoder = decoder
def forward(self, x: Tensor, embedding_ = False):
if embedding_ is not True:
return self.decoder(self.encoder(x))
else:
return self.encoder(x)
AE_model = Autoencoder_layer(Encoder_layer(sws = 512, embedding_dim = 2), Decoder_layer(sws = 512, embedding_dim = 2))
I am applying MSE for loss function and Adam for optimization function in a typical training framework.
The learning rate starts from around 1.3e^-3 and decreases gradually.
And here is some description (also picture below) about data the model tries to learn for reconstruction (red) and resulting reconstruction (blue). The training dataset has size of (9856 x 512); in other words 9856 samples with 512 points in each sample. The plot is from flattened dataset and reconstruction result.
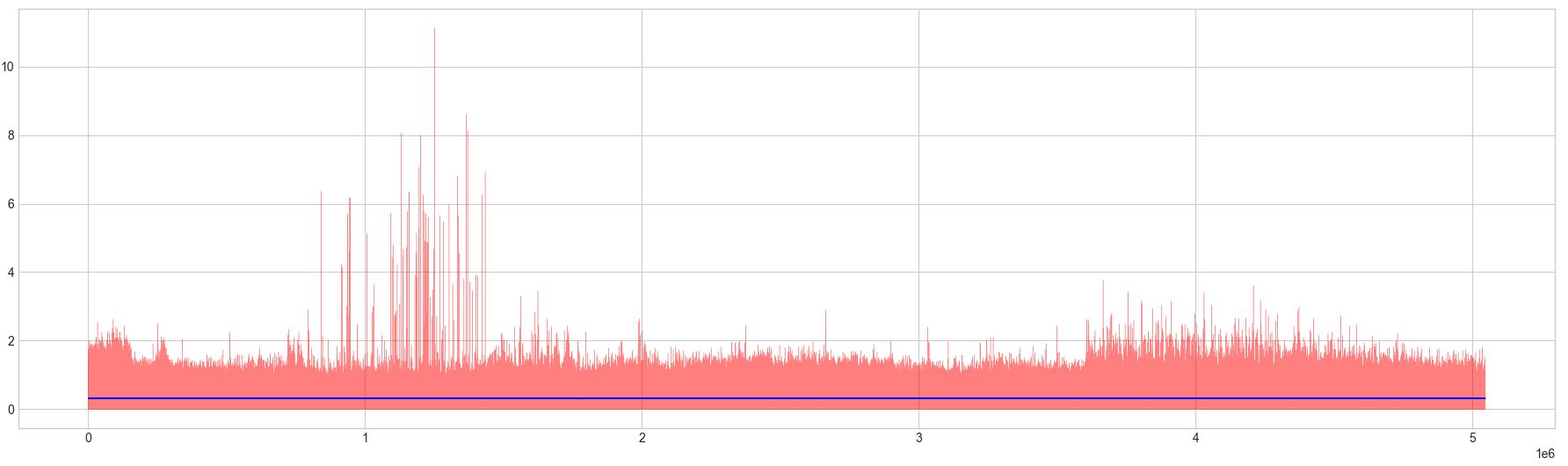
This was with batch size of 32 and epochs of 120 with early stopping applied, so the actual training epochs taken were 50. This resulted in loss of around 0.0557. As shown in the plot, the model obviously did not learn well. Also, I tried to test it in many different ways such with different batch size, network complexity (deeper network), input size, optimization parameters, activation functions, another variant (variational AE), absolute input (as one in the plot), etc. Noted that when absolute input was applied, the best loss (0.0557) was achieved. If I use non-absolute input then, the best loss gives around 0.14.
I think I need to get the loss at least down to around 0.002 or 0.003 to see some result. This estimation was obtained from my previous test using another network (Transformer encoder) from which the reconstruction result was very satisfactory. FYI, the complexity of the Transformer encoder was around 1M whereas the AE has the learnable parameters of 140,292. The Transformer encoder takes in 32 sequences with 256 vectors embedded from 80 points in each sequence.
I am guessing how the training is done is okay, but the problem seems to be in either in the network or the way I apply the data to the model. So, regarding why my AE fails to reconstruct the original data, my questions are
-
Is this because the AE has low complexity (as in the small number of parameters), so the its optima is just loss of around 0.0557?
-
What else can I try to improve the loss apart from the mentioned ones?
-
Would applying so-called stacked autoencoder (or any other variants) ever improve it?
-
Any mistake do you see it from the set-up or the model?
and here is one more question on another note.
- I intentionally did not apply normalization (min-max or z-norm) to input data because this is not applicable for my task. But, I am wondering how you guys deal with the training datasets being shifted (in terms of mean) significantly from each other when applying min-max norm due to outliers?
Please feel free to leave any comments. I am new to this forum. If I am not providing sufficient information please let me know.