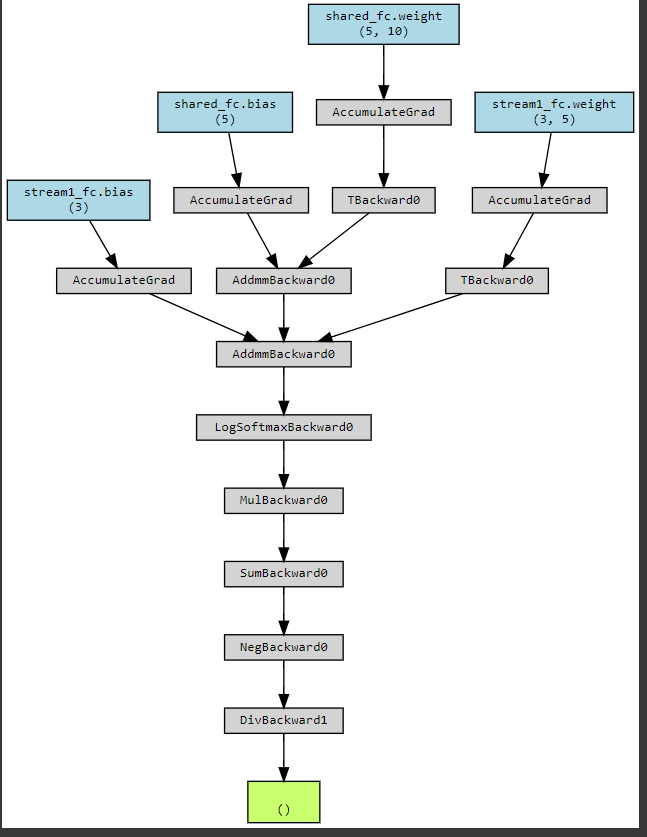
i need to make sure my loss1 impacts stream 2 in the back propagation. how can i visualize the backward parth of the loss? i used make_dot to get the graph. but it does not solve my problem because when i visualize the graph belongs to loss1, it does not have any impact with the weights of stream2.
please help me to understand the pytorch backwards function.
loss1 won’t directly contribute to the gradient calculation on stream2 since no parameters in stream2 were used to calculate loss1, so there is no direct dependency.
However, stream2 consumes out_shared created by shared_layer, which was used to compute loss1, so its gradients will be affected by loss1.
Thank you for the reply @ptrblck !! But what if i use the total loss = loss1* loss2 for the backpropagation. Then the loss1 should have a contribution to update the weights in the stream2. I wrote the partial derivatives. Please guide me if i did any mistake !! as well as let me know that pytorch backwards can handle this case as i wrote in the picture
Thank you @ptrblck .
yes i’m multiplying losses .
so if i use the torchviz to visualize the gradient path as in the following code, does it give the result of backpropagation with respect to loss1 ?
I’m confused because it does not involve any parameter related to stream 2 as shown in the graph.
import torch
import torch.nn as nn
import torch.optim as optim
import torch.optim as optim
from torchviz import make_dot
from torch.utils.tensorboard import SummaryWriter
writer = SummaryWriter()
class SharedLayerNet(nn.Module):
def __init__(self):
super(SharedLayerNet, self).__init__()
self.shared_fc = nn.Linear(10, 5) # Shared layer
self.stream1_fc = nn.Linear(5, 3) # First stream
self.stream2_fc = nn.Linear(5, 2) # Second stream
def forward(self, x):
shared_out = self.shared_fc(x) # Shared layer output
out1 = self.stream1_fc(shared_out) # First stream output
out2 = self.stream2_fc(shared_out) # Second stream output
return out1, out2
model = SharedLayerNet()
criterion1 = nn.CrossEntropyLoss()
criterion2 = nn.CrossEntropyLoss()
optimizer = optim.SGD(model.parameters(), lr=0.01)
input_data = torch.randn(1, 10) # Input data of shape (batch_size, input_size)
# Forward pass
out1, out2 = model(input_data)
# Compute losses
loss1 = criterion1(out1, torch.randn(1, 3)) # MSE loss in first stream
loss2 = criterion2(out2, torch.tensor([1])) # Cross-entropy loss in second stream
# Compute total loss
total_loss = loss1 + loss2
# Backward pass
optimizer.zero_grad()
loss1.backward(create_graph = True)
optimizer.step()
# Visualize computational graph and gradients
make_dot((loss1), params=dict(model.named_parameters()))
I don’t know if torchviz is able to display all related tensors and it also seems this library wasn’t updated in ~2 years, so I’m also unsure if it’s still being maintained or not.
yeah me too. because it gave the same graph for both loss1+loss2 and loss1*loss2. So do you know if there is a method to make sure that stream2 weights are updated using both loss1 and loss2?. it is better if we can visualize the backpropagation path for a simple network like the above.
I appreciate your consideration @ptrblck !! thank you very much.