Hi Yoav!
Curiouser and curiouser …
I have some clarifying questions and a couple of suggestions.
To confirm:
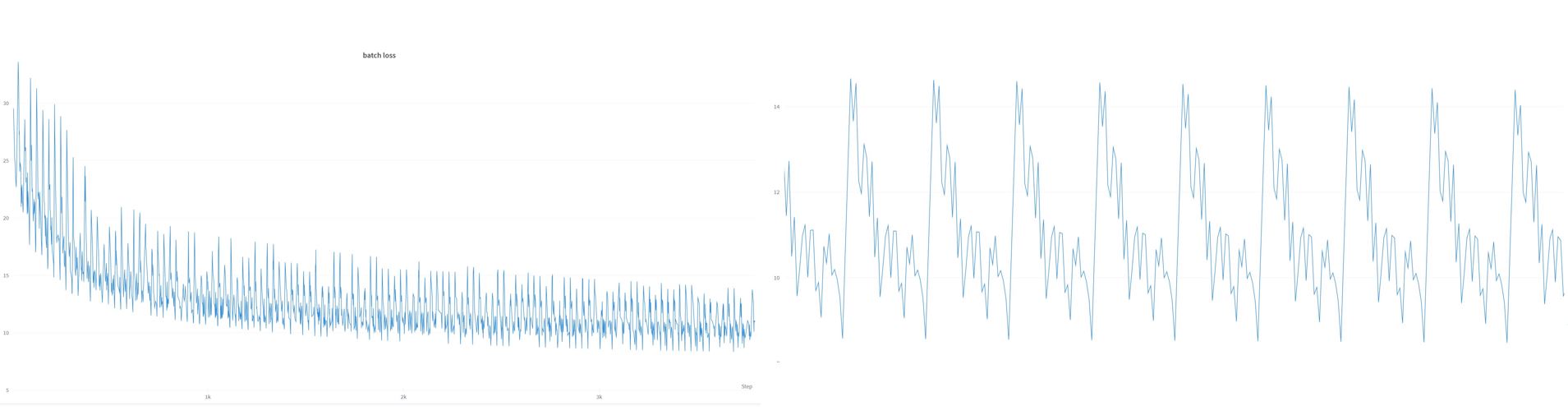
Do you mean by this that every epoch contains the exact same sequence
of batches (in the same order) every time through? (And that each specific
batch at a given position within the epoch contains the exact same data
samples?)
Did you mean that the distance between repeating peaks is 31 batches or is
it indeed “31 epochs,” as you said? “Batches” seems to fit the context better.
If it is batches, could you confirm that the periodicity really is different than the
number of batches in an epoch? This looks very much as if as you go through
the same sequence of batches you get approximately-matching patterns in
your loss function. It would seem very odd if as you go through the same
sequence of batches from epoch to epoch, different batches give you “matching”
values of the loss function (for example, different batches give you the peak).
Are you using any sort of learning-rate scheduler?
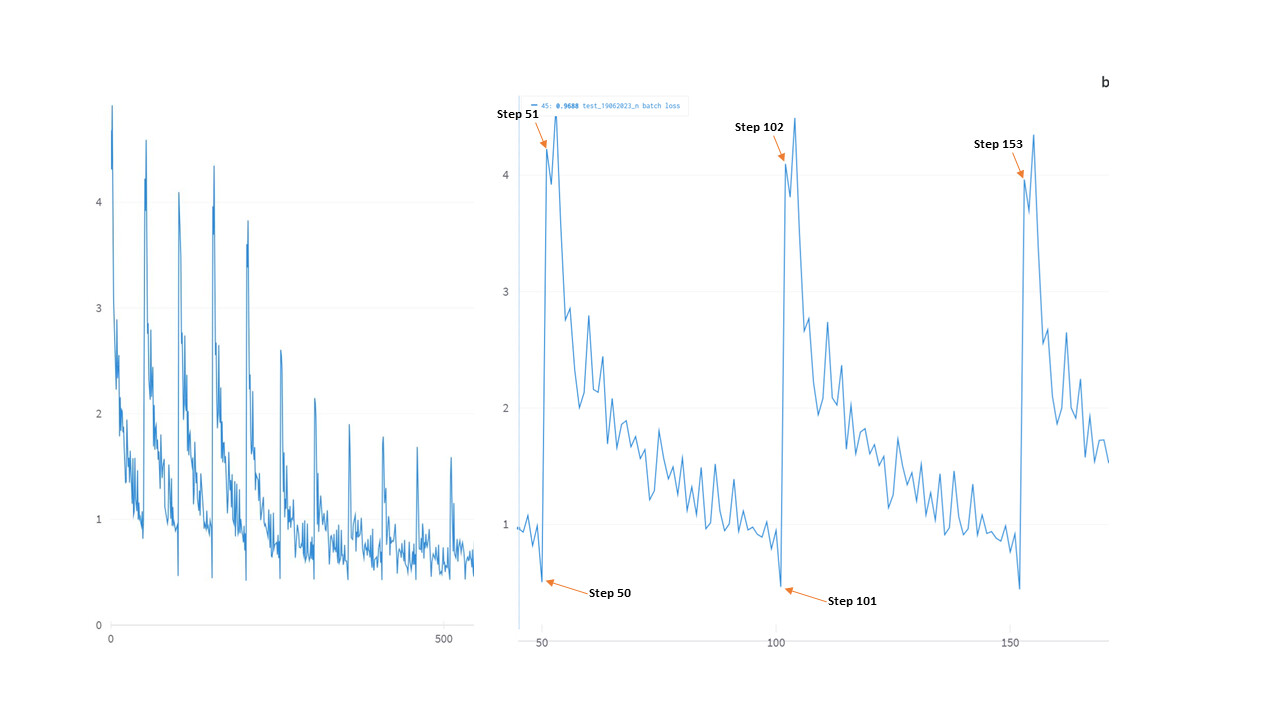
Could you post your zoomed-in loss graph, annotating the top peak and bottom
valley (as well as, perhaps, a couple other landmarks) with the batch number
(or epoch number, if they really are epochs)?
Try making the same graph with training turned off. That is, run the exact same
code, but simply skip the optimization step or maybe set the learning rate to
zero. (You might also try training for a bit before turning off the training just to
let things stabilize a little bit.)
Assuming that you are using pytorch’s DataLoader class, you might try setting
drop_last = True. I think its a long shot (because the last-batch size of 62 is
really not that different from 80), but maybe your last batch is giving your training
an unhelpful jolt that causes your loss function to spike up.
And, yes, turning on shuffling would make sense, but that would mask the
interesting effect that you’re currently seeing.
Best.
K. Frank