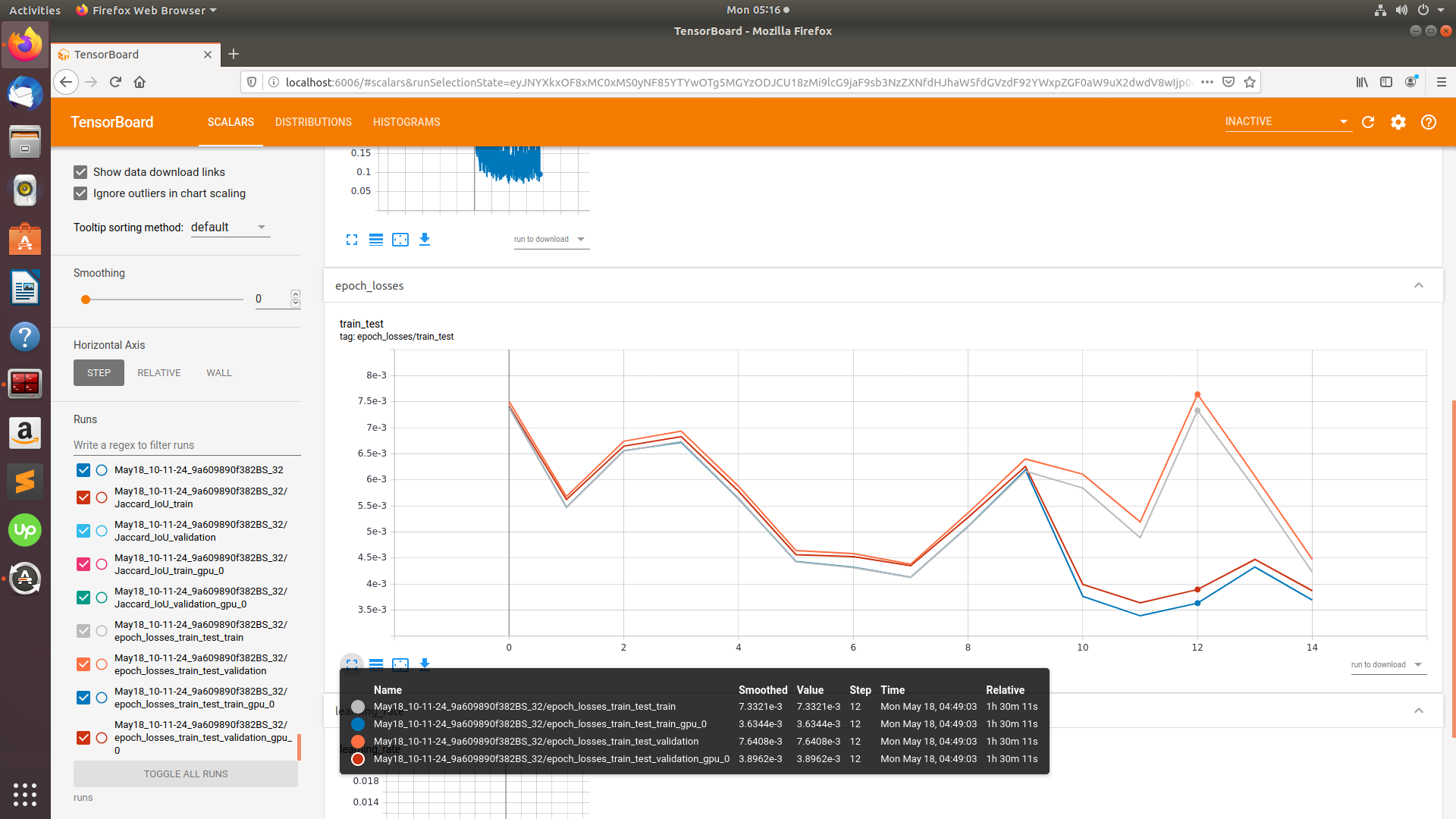
I have stumbled upon a problem when using DistributedDataParallel. Strangely, after a few epochs of successful training, loss goes up for a while. I noticed that both train/validation losses got down for the batches which are on GPU0, but go up for the other 3 GPUs. I believe I’m doing something wrong with DistributedDataParallel, but can’t find a bug. Did anyone see a similar problem, or can guess what the reason can be?
In the chart you can see training and validation losses for GPU0 and average of all 4.
Hey @Martun_Karapetyan, DDP should have kept all model replicas in sync, i.e., all model replicas should have the same parameter values. Could you please check if this is true in your use case, say by using all_gather to collect all model parameters into one rank and compare?
I checked the model parameters, they were in perfect sync.
I had another stupid bug. I used ReduceLROnPlateau when the validation accuracy plateaued, but each process looked at the validation accuracy of its subset of data. 1st process reduced the learning rate first, the others reduced it 1 epoch later, hence the problem.