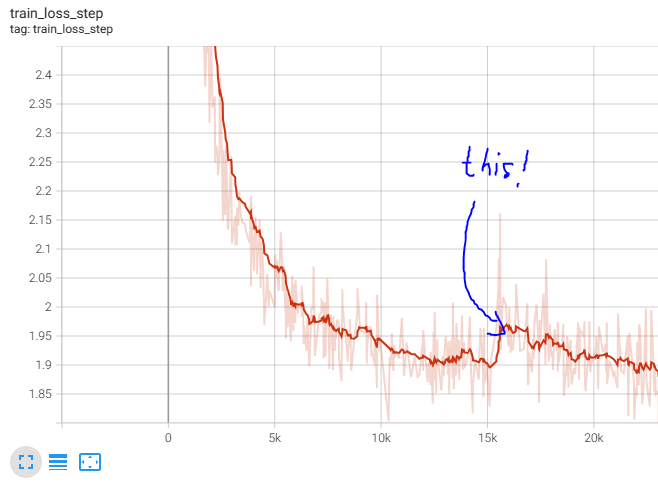
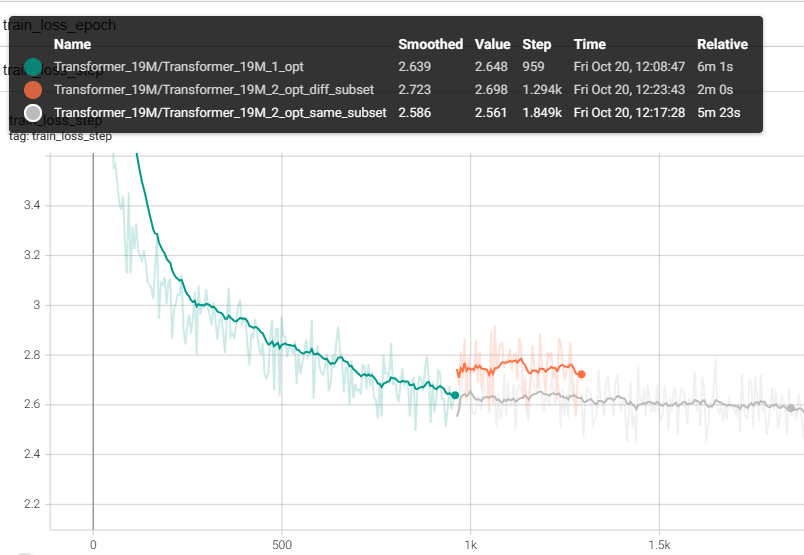
I am training a Transformer encoder-decoder model for machine translation in pytorch lightning. My dataset is too large to train the model in one go, so I decided to split the training data into 10 subsets. Entire training process consists of iterating once through every subset (every batch is seen only once). After training model on first subset and loading second one, loss goes up.
This is unexpected since subsets were created by shuffling entire training data, so they do not differ much from one another. Problem does not occur when I load the same subset for the second time. (unfortunately new users can not put multiple images in one post so I can’t post it here…) Also this does not happen when I merge two subsets into one and train model on merged subset. This suggets that the issue is with checkpointing.
My first guess was that optimizer states or learning rate was reset, but after further investigation this is not the case.
I am using lightning checkpoining and following versions of packages:
torch==2.0.1 torchvision torchaudio torchtext
pytorch-lightning==2.0.1
xformers==0.0.20
triton==2.0.0.dev20221105 --no-deps
According to documentation when I pass ckpt_path argument to trainer.fit it will load model, epoch, step, LR schedulers, apex, etc. If optimizer state was erased then loss should increase no matter which subset is loaded, am I right? But when I load the same subset for the second time loss goes down smoothly.
So have you try this? If you still get a higher loss on new subset but the same loss on old subset, I think everything goes well for the checkpointing.
I’m not very familiar with NLP tasks. Is there any data sample in your dataset using the same input but different labels?
For example, in the Visual Grounding task, if I have an image, the dataset may have some different sentences to describe something in this image. These sentences have the same inputs (image) but different labels (bounding box). During training an epoch, I may only see the specific sentence only once, but the same image more than once. It may lead the loss being lower on the train set (old subset) than a new set (new subset).
I do not think so. I filtered and de-duplicated training set it does not contain same/similar sentences. Weird behaviour probably has to do with bad sampling. I will investiage it further and give response asap!
How does the loss of training for 2 epochs on the same dataset, vs the loss of 1 epoch on the concat of the same dataset? (without shuffling)
Also curious why you think this is normal, it seems like a significant bump ( especially when you see that it’s happening in the first steps)
If you’re training the model on different subsets of the dataset, one can expect the loss to increase initially for each change in subset.
Based on what you’ve said, let’s establish that:
The subsets are not identical to each other,
Training a model on a given subset reduces loss on that subset only.
Suppose they are 10% different from each other. Then 90% of the training on the first subset will generalize to the other subsets. But 10%, which represents the difference, will not generalize to the other subsets. Hence the bump in loss.