Hello everyone’s. I try to use Mean-Teacher architecture with two U-Net in a semi-supervised setup but I have a strage behaviour with the loss during the training. I have a supervised loss and a contrastive loss computed on unlabled data that then i sum it and obatin a loss for backpropagation
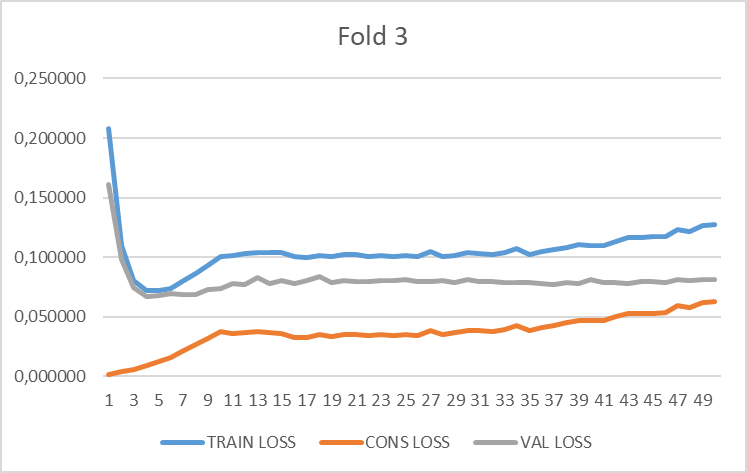
This is an example of my training. It would appear that contrastive loss contribution dont’ backpropagate.
I had checked if the loss contribution had required_grad = True and all my loss have this parameter setted at True value.
This is my trainer function:
def _train(self,writer):
self.model.train() # train mode
self.ema_model.train() # train mode
cons = torch.as_tensor(0, dtype=torch.float32, device=device)
cons_weight = torch.as_tensor(0, dtype=torch.float32, device=device)
temp = [] # accumulate the losses here
n_batch = 0
batch_iter = tqdm(enumerate(self.training_DataLoader), 'Training', total=len(self.training_DataLoader), leave=False)
for i_batch, (x,y) in batch_iter:#enumerate(trainloader):
n_batch += 1
volume_batch, label_batch = x,y[0]#sampled_batch['image'], sampled_batch['label']
volume_batch, label_batch = volume_batch.cuda(), label_batch.cuda()
unlabeled_volume_batch = volume_batch[self.labeled_bs:]
noise = torch.clamp(torch.randn_like(unlabeled_volume_batch) * 0.1, -0.2, 0.2)
ema_inputs = unlabeled_volume_batch + noise
outputs = model(volume_batch)
with torch.no_grad():
ema_output = ema_model(ema_inputs)
T = 8
volume_batch_r = unlabeled_volume_batch.repeat(2, 1, 1, 1)
stride = volume_batch_r.shape[0] // 2
preds = torch.zeros([stride * T, 1, 384, 384]).cuda()
for i in range(T//2):
ema_inputs = volume_batch_r + torch.clamp(torch.randn_like(volume_batch_r) * 0.1, -0.2, 0.2)
with torch.no_grad():
preds[2 * stride * i:2 * stride * (i + 1)] = ema_model(ema_inputs)
preds = F.softmax(preds, dim=1)
preds = preds.reshape(T, stride, 1, 384, 384)
preds = torch.mean(preds, dim=0) #(batch, 2, 112,112,80)
# uncertainty = -1.0*torch.sum(preds*torch.log(preds + 1e-6), dim=1, keepdim=True) #(batch, 1, 112,112,80)
uncertainty = -1.0*torch.sum(label_batch[self.labeled_bs:]*torch.log(preds + 1e-6), dim=1, keepdim=True) #(batch, 1, 112,112,80)
weights = F.softmax(1 - uncertainty, dim=0) # weight map = softmax(confidence map)
ema_probs = torch.sum(preds * weights, dim=0) # integration result
ema_seg_uncertainty = -1.0 * torch.sum(ema_probs * torch.log2(ema_probs + 1e-6), dim=1, keepdim=True) # U_seg
## calculate the loss
supervised_loss = criterion(outputs[:self.labeled_bs], label_batch[:self.labeled_bs])
# consistency_weight = get_current_consistency_weight(iter_num//150)
consistency_weight = get_current_consistency_weight(self.epoch)
# consistency_weight = 0.1 * math.exp(-5 * math.pow((1 - self.epoch / self.epochs), 2))
# consistency_weight = args.consistency * math.exp(-5 * math.pow((1 - self.epoch / self.epochs), 2))
# consistency_dist = consistency_criterion(outputs[labeled_bs:], ema_output) #(batch, 2, 112,112,80)
consistency_dist = torch.pow(outputs[self.labeled_bs:] - ema_output, 2) #(batch, 2, 112,112,80)
# threshold = (0.75+0.25*ramps.sigmoid_rampup(self.iter_num, len(self.training_DataLoader)*self.epochs))*np.log(2)
# mask = (uncertainty<threshold).float()
# consistency_dist = torch.sum(mask*consistency_dist)/(2*torch.sum(mask)+1e-16)
consistency_dist = consistency_dist * (1 - ema_seg_uncertainty)
consistency_dist = torch.mean(consistency_dist)
consistency_loss = consistency_weight * consistency_dist
cons += consistency_loss
cons_weight += consistency_weight
if n_batch == 1:
a = supervised_loss.item() + consistency_loss.item()
b = supervised_loss.item()#dice.item()
else:
a = a + supervised_loss.item() + consistency_loss.item()
b = b + supervised_loss.item()#dice.item()
loss = supervised_loss + consistency_loss
optimizer.zero_grad()
loss.backward()
optimizer.step()
update_ema_variables(model, ema_model, args.ema_decay, self.iter_num)
self.iter_num = self.iter_num + 1
logging.info('Epoch %d | iteration %d : loss : %f, sup_loss: %f, consistency_loss: %f, cons_dist: %f, loss_weight: %f' %
(self.epoch, self.iter_num, loss.item(),supervised_loss.item(), consistency_loss.item(), consistency_dist.item(), consistency_weight))
self.report_losses.append(temp)
print(" CONSISTENCY LOSS: ", round(cons.item() / n_batch, 5), cons_weight.item() / n_batch)
losses = a / n_batch ###
print(" TRAIN LOSS: ", losses)
self.task_losses.append([b / n_batch, round(cons.item() / n_batch, 5), cons_weight.item() / n_batch])
self.training_loss.append(losses)
self.consistency_loss.append(round(cons.item() / n_batch, 6))
self.learning_rate.append(self.optimizer.param_groups[0]['lr'])
torch.save(self.model.state_dict(), self.model_name)
print("Model Saved")
and this is how create models:
def create_model(ema=False):
# Network definition
model = UNet(1, 1)
model = model.cuda()
if ema:
for param in model.parameters():
param.detach_()
return model
model = create_model()
ema_model = create_model(ema=True)
criterion = MultiTaskLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-4)
Thanks in advance