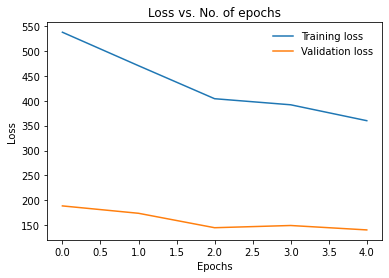
Hi, the first time I trained the model, the loss started with 1.0 and gradually decreased on both train and validation. but whenever I re-run it again, it increases. It seems like it is counting the previous loss together. I am doing a binary classification. What can I do to stop adding the loss every time I run? I know we should initialize the weight of the model. How can I do this inside my architecture? Do I need to use a fixed seed? if so how to use this? this is my code snippet
#original code
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
#refer the article ...
self.conv1 = nn.Sequential(
nn.Conv1d(1, 32, kernel_size=2, stride=1),
nn.Dropout(0.5),
nn.ReLU())
self.conv2 = nn.Sequential(
nn.Conv1d(32,32, kernel_size=2, stride=1),
nn.Dropout(0.5),
nn.ReLU(),
nn.MaxPool1d(2,stride=3))
self.conv3 = nn.Sequential(
nn.Conv1d(32, 32, kernel_size=2, stride=1),
nn.Dropout(0.5),
nn.ReLU())
#fully connected layers
self.fc1 = nn.Linear(32*47,32)
#self.fc2 = nn.Linear(32,1)
self.fc2 = nn.Linear(32,1)
#self.activation = nn.Softmax()
#self.activation = nn.Sigmoid()
# Initialization
#nn.init.normal_(self.fc1.weight)
#nn.init.normal_(self.fc2.weight)
def forward(self, x):
# input x :
#expected conv1d input = minibatch_size * num_channel * width
batch_size=x.size(0)
y = self.conv1(x.view(batch_size,1,-1))
y = self.conv2(y)
y = self.conv3(y)
#print(y.size())
batch_size= y.size(0)
y = y.flatten(start_dim=1)
#print(y.size())
y = self.fc1(y.view(y.size(0), -1))
#y = self.fc1(y.view(batch_size,1,-1))
y = self.fc2(y.view(batch_size,1,-1))
return y
This is what I get when I run the model.
total confusion matrix
Accuracy tensor(0.8333)
Sensitivity tensor([0.9778, 0.7279])
PPV tensor([0.7239, 0.9782])
Epoch 1 Training Loss: 4.26098953670633 Validation Loss: 9.583865708112716
Validation Loss Decreased(inf--->287.515971) Saving The Model
total confusion matrix
Accuracy tensor(0.7490)
Sensitivity tensor([0.9975, 0.5691])
PPV tensor([0.6262, 0.9969])
Epoch 2 Training Loss: 4.444644435301871 Validation Loss: 16.55208384990692
total confusion matrix
Accuracy tensor(0.7406)
Sensitivity tensor([1.0000, 0.5569])
PPV tensor([0.6151, 1.0000])
Epoch 3 Training Loss: 3.656472649733375 Validation Loss: 17.436482475201288
total confusion matrix
Accuracy tensor(0.9479)
Sensitivity tensor([0.9879, 0.9177])
PPV tensor([0.9007, 0.9901])
Epoch 4 Training Loss: 3.4676516719190476 Validation Loss: 5.442984523872535
Validation Loss Decreased(287.515971--->163.289536) Saving The Model