For some reason, my loss is increasing instead of decreasing.
These are my train/test functions:
def train(model, device, train_input, optimizer, criterion, epoch):
model.train()
len_train = len(train_input)
batch_size = args['batch_size']
for idx in range(0, len(train_input), batch_size):
optimizer.zero_grad()
batch = train_input[idx: idx + batch_size]
X, y = get_batch(batch, device)
output = model(X)
loss = criterion(output, y)
loss.backward()
optimizer.step()
pred = output.max(1, keepdim=True)[1]
correct = pred.eq(y.view_as(pred)).sum().item()
if idx % 400 == 0:
print("\nTrain epoch {} / {} [{} - {} / {}]\nLoss = {:.4}\nOutput = {}\n".format(epoch,
args['n_epochs'], idx, idx + batch_size, len_train, loss / batch_size, output))
print('Correct {}'.format(correct))
def test(model, device, test_input, criterion):
model.eval()
test_loss = 0
correct = 0
batch_size = args['batch_size']
with torch.no_grad():
for idx in range(0, len(test_input), batch_size):
batch = test_input[idx: idx + batch_size]
X, y = get_batch(batch, device)
output = model(X)
test_loss += criterion(output, y)
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(y.view_as(pred)).sum().item()
if idx % 10 == 0:
print('Pred {} Label {}'.format(pred, y))
test_loss /= len(test_input)
validation_data['loss'].append(test_loss)
validation_data['acc'].append(correct / len(test_input))
print("\nTest set: Average Loss: {:.4}, Accuracy: {}".format(test_loss,
correct / len(test_input)))
These are the criterion and optimizer:
optimizer = optim.Adam(model.parameters(), lr=args[‘initial_lr’], weight_decay=args[‘weight_decay’], amsgrad=True)
criterion = nn.CrossEntropyLoss().cuda()
Why is the loss increasing? The validation accuracy is increasing just a little bit.
Loss graph:
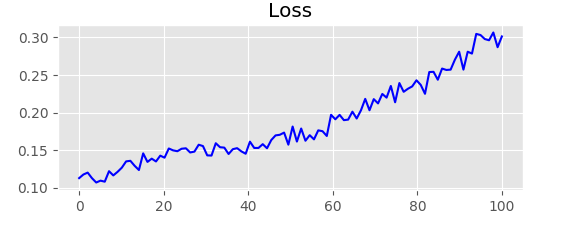
Thank you.
