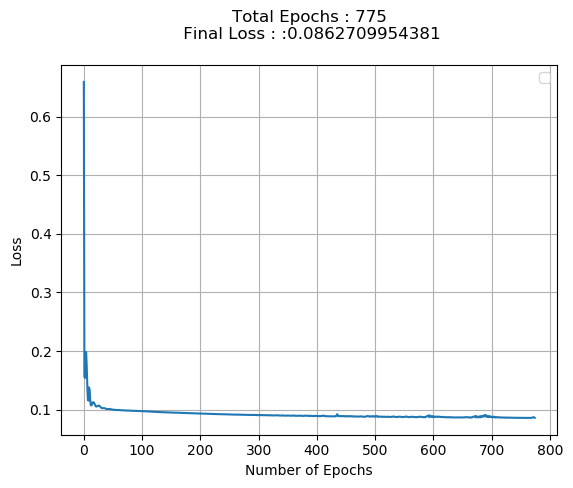
Dataset is 1.7 M data points, 1.36 M Train & 350 K Test , to perform binary classification.Initially i didn’t use batch size and directly fed the training and saw Loss decreasing with increase in epochs (upto 775) for a suitable config as shown below
Post then , to cover variance ,introduced Data Loader & Tensor data and gave batch size of 128 in code shown below:
n_input_dim = X_train.shape[1]
# Layer size
n_hidden1 = 200
n_hidden2 = 180
n_hidden3 = 150
n_output = 1
model = nn.Sequential(
nn.Linear(n_input_dim, n_hidden1),
nn.ReLU(),
nn.Linear(n_hidden1, n_hidden2),
nn.ReLU(),
nn.Linear(n_hidden2, n_hidden3),
nn.ELU(),
nn.Linear(n_hidden3, n_output),
nn.Sigmoid())
scaler = preprocessing.MinMaxScaler()
xtrain_norm = scaler.fit_transform(X_train.values)
x_tensor = torch.from_numpy(xtrain_norm).float()
y_tensor = torch.from_numpy(Y_train).float()
batch_sz = 128
learning_rate = 0.01
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
train = data_utils.TensorDataset(x_tensor, y_tensor)
trainloader = data_utils.DataLoader(train, batch_size=batch_sz, shuffle=True)
epochs = 775
for i in range(epochs):
for j,data in enumerate(trainloader,0):
input,labels = data
# wrap them in Variable
input, labels = Variable(input), Variable(labels)
y_pred = model(input)
loss = loss_func(y_pred, labels)
optimizer.zero_grad()
loss.backward()
optimizer.step()
However , post using batch size Loss doesn’t seem to decrease as depicted below:
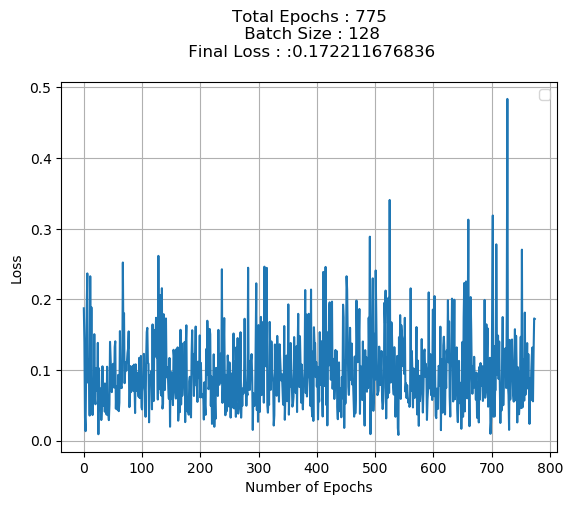
What is going wrong ? Shouldn’t with every iteration run and correspondingly every epoch run Loss should show decrease as was the case without batch size introduction ?