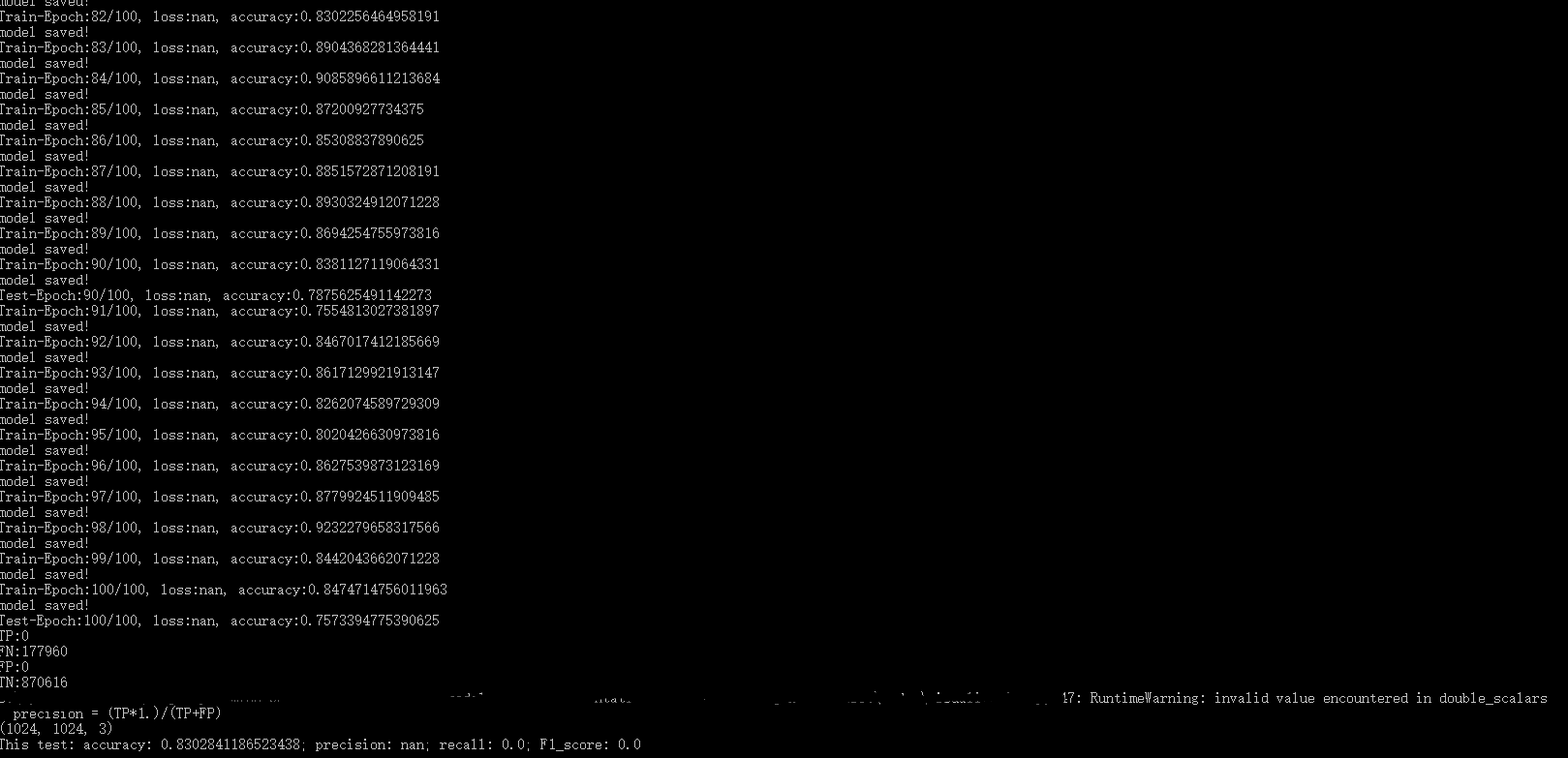
What is your data distribution? Do you have 2 classes where 1 is ~80% of data?
I think this is your situation (exaclly 870k of majority class and 170k of second one). So when you will be predicting just majority class, you will have very nice accuracy.
In Summary, your model doesn’t learn anything useful.
Also, you have in your output much better metrics, like precision,recall, F1 score. Monitor this one, not pure accuracy (or accuracy per class)