Hi there,
I’m trying to implement a very simple model (multi layer perceptron) to tackle a binary classification problem but the loss function does not decrease and is saw-shaped.
I do have very few labelled samples: (train (60) | test (15)). The input data is tabular from 7 different data types, which is then normalized (max-min):
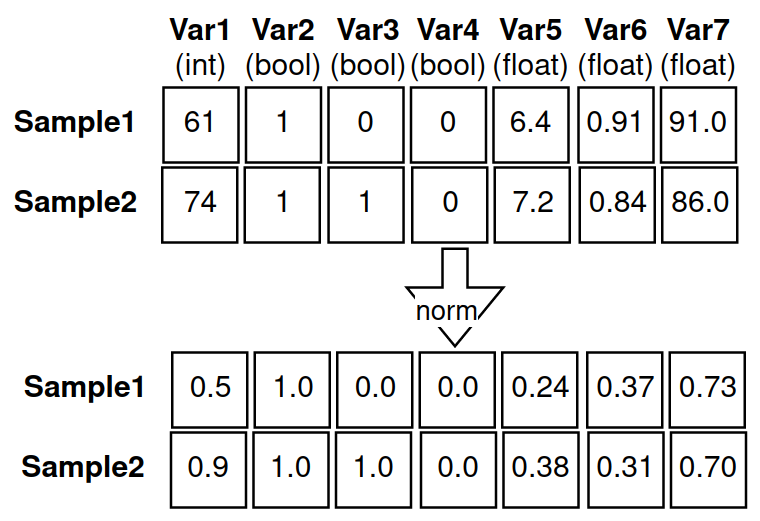
Each sample belong to class 0 or 1
The model:
class CustomModel(nn.Module):
def __init__(self, ):
torch.manual_seed(3)
super(CustomModel, self).__init__()
self.fc1 = nn.Linear(7, 60)
self.fc2 = nn.Linear(60, 100)
self.fc3 = nn.Linear(100, 30)
self.fc4 = nn.Linear(30, 2)
self.apply(self._init_weights)
def _init_weights(self, module):
if isinstance(module, nn.Linear):
torch.nn.init.xavier_uniform_(module.weight.data)
torch.nn.init.constant_(module.bias.data, 0)
def forward(self, data):
x = data
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = F.relu(self.fc3(x))
x = self.fc4(x)
return x
The training process:
# model instance
model = CustomModel()
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# Optimizer and criterion
optimizer = optim.SGD(model.parameters(), lr=0.0001)
criterion = nn.CrossEntropyLoss()
model.train(True)
for i in range(1000):
for i, batch in enumerate(train_loader):
sample, ground= batch
sample = sample.to(device=device, dtype=torch.float32)
ground = ground.to(device=device, dtype=torch.long)
optimizer.zero_grad()
prediction = model(sample)
loss = criterion(prediction, ground)
loss.backward()
optimizer.step()
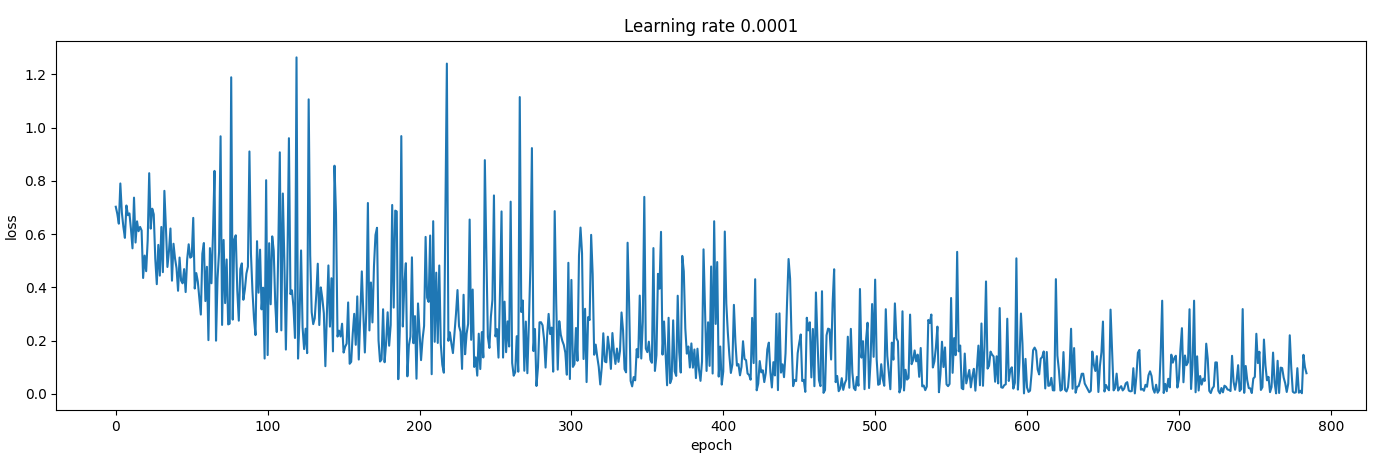
And the obtained loss function:
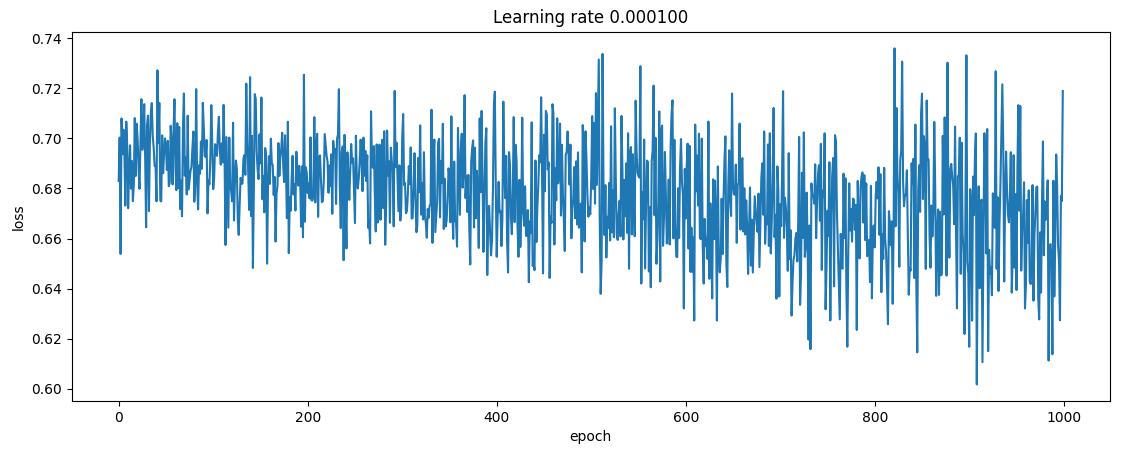
I don´t know where the problem might be: data processing, model definition or the training process itself. Batch size is set to 8. I have checked out the model parameters are updating (slightly but not much).
Looking to the gradients at last layer at some point the are few values to 0.0 so, I don´t know if this could be the problem.
print(list(model.parameters())[6].grad)
tensor([[ 0.0032, -0.0025, 0.0000, 0.0000, 0.0025, -0.0045, 0.0214, 0.0219,
0.0102, 0.0052, -0.0004, -0.0027, 0.0000, -0.0109, 0.0008, 0.0020,
0.0000, 0.0024, 0.0000, 0.0161, 0.0000, 0.0041, 0.0000, -0.0058,
0.0078, -0.0006, 0.0000, 0.0060, 0.0049, 0.0027],
[-0.0032, 0.0025, 0.0000, 0.0000, -0.0025, 0.0045, -0.0214, -0.0219,
-0.0102, -0.0052, 0.0004, 0.0027, 0.0000, 0.0109, -0.0008, -0.0020,
0.0000, -0.0024, 0.0000, -0.0161, 0.0000, -0.0041, 0.0000, 0.0058,
-0.0078, 0.0006, 0.0000, -0.0060, -0.0049, -0.0027]])
Thanks in advance.