I have implemented Dense Passage Retrieval in the below class, the idea is as given in the figure
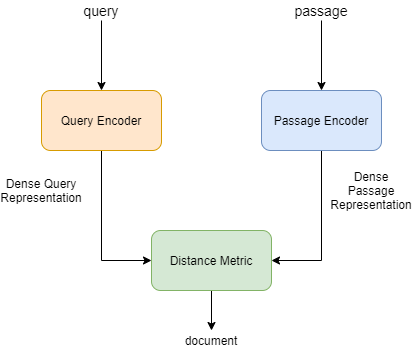
I am using AlbertModel for query_model and RobertaModel for passage_model
The objective of the network is to maximize the dot product between the correct passage and the query.
class DPR(nn.Module):
def __init__(self, query_model, passage_model, dense_size):
super(DPR, self).__init__()
self.query_model = query_model
self.passage_model = passage_model
self.passage_to_dense = nn.Linear(768, dense_size)
self.query_to_dense = nn.Linear(768, dense_size)
self.sigmoid = nn.Sigmoid()
def dot_product(self, q_vector, p_vector):
q_vector = q_vector.unsqueeze(1)
sim = torch.matmul(q_vector, torch.transpose(p_vector, -2, -1))
return sim
def forward(self, context_input_ids, context_attention_mask, query_input_ids, query_attention_mask):
dense_passage = self.passage_model(input_ids = context_input_ids, attention_mask = context_attention_mask)
dense_query = self.query_model(input_ids = query_input_ids, attention_mask = query_attention_mask)
dense_passage = dense_passage['pooler_output']
dense_query = dense_query['pooler_output']
dense_passage = self.passage_to_dense(dense_passage)
dense_query = self.query_to_dense(dense_query)
similarity_score = self.dot_product(dense_query, dense_passage)
similarity_score = similarity_score.squeeze(1)
return similarity_score
After training the model, I have come to notice that the dense representation produced by passage_model for any passage is the same and all dense representation for different queries are also the same
The training loop as given below
criterion = nn.BCEWithLogitsLoss()
optimizer = torch.optim.AdamW(dpr_model.parameters(), lr = 5e-5)
for i in range(iterations):
context_input_ids_tensor,context_attention_mask_tensor,query_input_ids,query_attention_mask = get_batch()
pred = dpr_model(context_input_ids_tensor,context_attention_mask_tensor,query_input_ids,query_attention_mask)
loss = criterion(pred, true.float())
loss.backward()
batch_loss += loss.item()
optimizer.step()
if i%20 == 0:
print(f"Batch : {int(i/20)} Loss : {batch_loss/20}")
batch_loss = 0
About the training data, the input to the model is one query and five passages, where one passage is correct and the rest of the four are negative samples. The output should maximize the similarity between the query with the positive passage and decrease the similarity between the query and the negative passages.
This is the log for the loss:
Batch : 1 Loss : 0.5550622567534447
Batch : 2 Loss : 0.49442077428102493
Batch : 3 Loss : 0.4927785858511925
Batch : 4 Loss : 0.5227641701698303
Batch : 5 Loss : 0.49368639290332794
Batch : 6 Loss : 0.5238333523273468
Batch : 7 Loss : 0.5037042826414109
Batch : 8 Loss : 0.5095990493893623
Batch : 9 Loss : 0.49853266924619677
Batch : 10 Loss : 0.49788044691085814
Batch : 11 Loss : 0.502707602083683
Batch : 12 Loss : 0.5041830345988274
Batch : 13 Loss : 0.5028198152780533
Batch : 14 Loss : 0.49953572899103166
Batch : 15 Loss : 0.506518942117691
..............................
The loss is stagnating at 0.5 and not decreasing after that.
Is there anything wrong with my logic or implementation. Or is there a better way of implementing the same architecture in Pytorch.