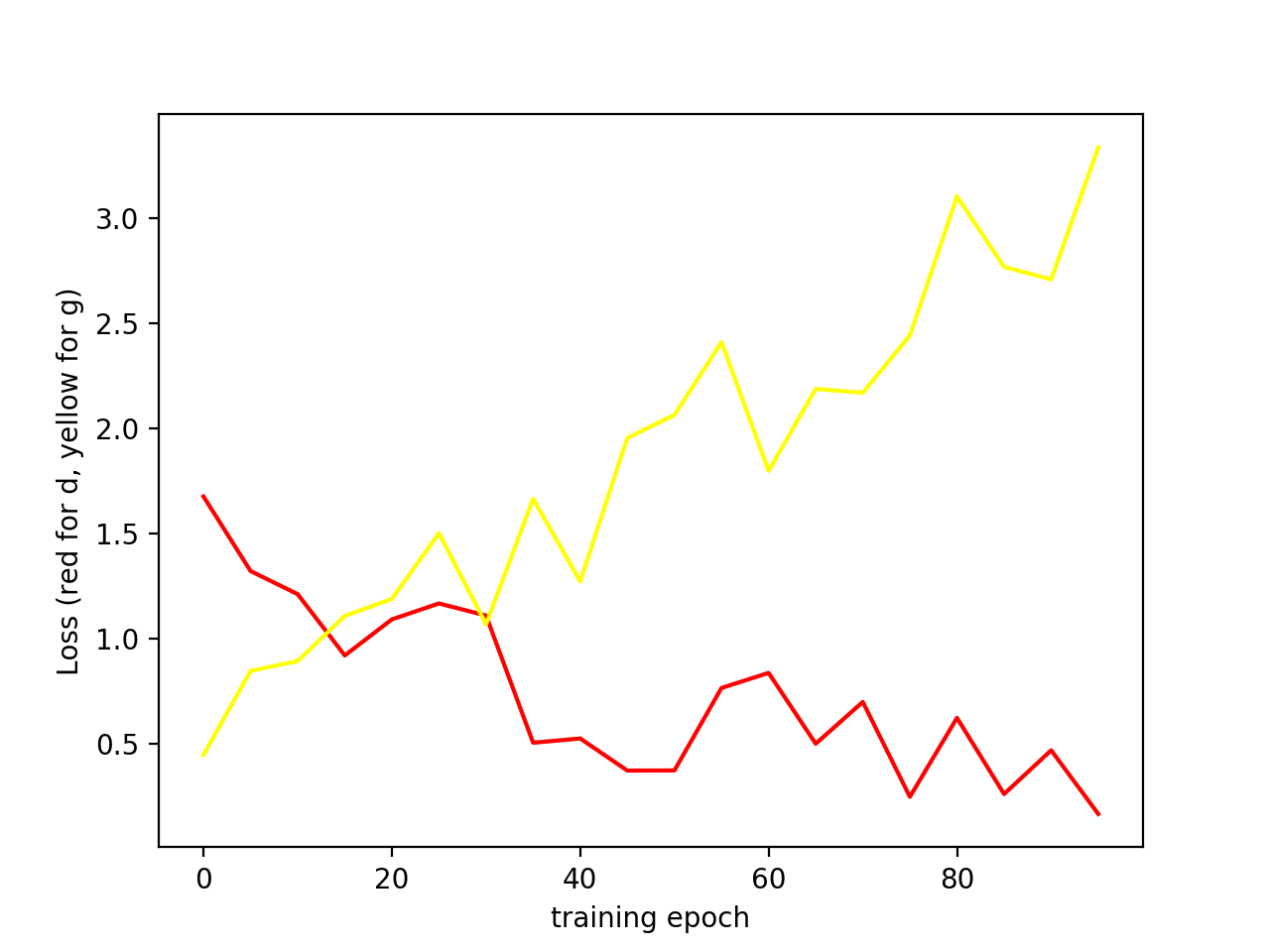
And as expected, the Prob_1 increases and Prob_2 decreases as the training goes, which means D is learning the right thing as expected.
Does this mean that the training of G and D are not balanced? G cannot keep up with D?
So intuitively, I think it would be better if G is trained more than D, but according to tips for training GAN, it would be a bad practice. (I tried other tips in this article like optimizers, activation functions, batchNorms etc.)
Would it be a good idea to train G more than D?
Or maybe there are some tips I should try?
GANs are a highly active topic for research. Generally GANs don’t converge well. A typical GAN loss should be something where G loss log(D(G(z)) maximizes and D loss log(D(x))+log(1-D(G(z)) minimizes. But that’s not the scenario all the time. Most of the time the discriminator gets fooled easily by the generator. To avoid this:
Update the discriminator more often than the generator.
Use WGAN with Gradient Penalty.
In some cases the discriminator gets an upperhand. To avoid this:
Add dropout and leaky relu in the discriminator layers.
Use label smoothing.
Add noise to both generated and real input before feeding them to the discriminator.
**Note: Don’t expect GAN to converge they may converge and may not. But usually if your generator and discriminator loss converges together then your GAN is good.