I’m obviously doing something wrong trying to finetune this implementation of Segnet. This is my results with accuracy and loss in TensorBoard.
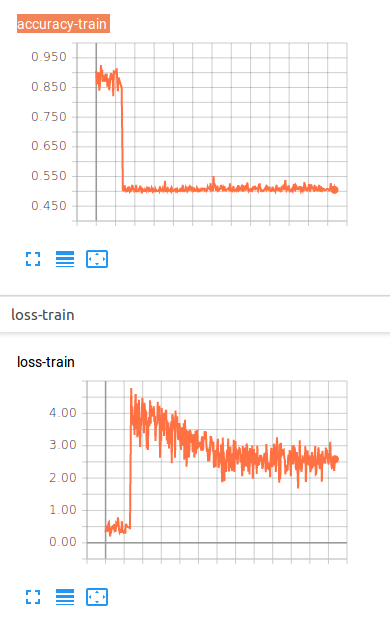
The loss graph has the right curve, but both functions present a very strange and wrong behaviour during the first training epoch. Based on accuracy, it almost looks like it performs finetuning correctly for the first epoch, then it starts from scratch.
This is the bare-bones of the code I’m working with:
def train(epoch):
model.train()
# update learning rate
exp_lr_scheduler.step()
total_loss = 0
total_accuracy = 0
# iteration over the batches
for batch_idx, (img, gt) in enumerate(train_loader):
input = Variable(img)
target = Variable(gt)
# initialize gradients
optimizer.zero_grad()
# predictions
output = model(input)
cr_en_loss = nn.CrossEntropyLoss()
loss = cr_en_loss(output, target)
loss.backward()
optimizer.step()
"""
Here I calculate accuracy for this batch and log results
"""
total_loss += loss.data[0]
total_accuracy += accuracy
return total_loss / len(train_loader), total_accuracy / len(train_loader)
# create SegNet model
model = SegNet(input_channels, label_numbers)
th = torch.load('path/of/pretrained/weights.pth')
model.load_state_dict(th)
# finetuning - freezing all the net's layers but the last one
ftparams = ['conv11d.weight', 'conv11d.bias']
for name, param in model.named_parameters():
if name not in ftparams:
param.requires_grad = False
# define the optimizer
optimizer = optim.SGD(model.conv11d.parameters(), lr=lr, momentum=momentum)
exp_lr_scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=step_size, gamma=gamma)
transform_train = transforms.Compose([
"""
Here I apply my transforms
"""
])
train_dataset = MyDataset(root_dir_img, root_dir_gt, transform_train)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=num_workers,
pin_memory=True
)
for epoch in range(epochs):
# training
train_loss, train_acc = train(epoch)
Where is my mistake? Why my net forgets everything starting from the second epoch?