Hi everyone! I’m currently working on a self-supervised learning model. And while building the model and training it works, every time when I start the training, my loss reduces quickly to zero or almost zero after the first epoch. I don’t quite understand the reason behind it because before I used as loss function the Cross-Entropy loss (without using logSoftmax and NLLLoss) and my loss was constantly at >1 (which wasn’t good either). I know it’s a lot to ask but does anybody have any advice on how to work on this problem? I would appreciate any input! ![]()
information about the training:
Batch_size = 64
Lr = 0.0001 (Tried already 0.001 and 0.1, except that the first epoch has a huge loss nothing really changes)
Size of my training set = 16303 (those are segments; each segment has around 3000 ‘rows’ of information for three different sensor types)
Class imbalance? = Yeah, I have a class imbalance but to counter that, I calculate class weights for each batch
Goal of the network (because it can look strange why I feed three different sensor types into the model): = Classifying for each sensor type which data augmentation was used on that certain type (according to this image: )
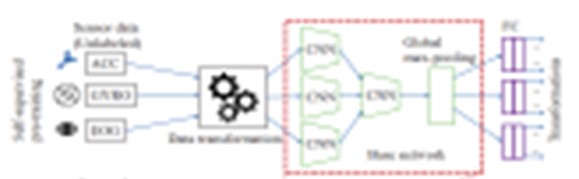
Here are my model and training’s process:
class BaseModel(nn.Module):
def init(self,
dropout_p=0.2):
super(BaseModel,self).init()# Kernel Sizes self.K24 = 24 self.K16 = 16 self.K8 = 8 self.K4 = 4 self.K2 = 2 # Output channels self.out_features32 = 32 self.out_features64 = 64 self.out_features96 = 96 self.out_features128 = 128 # CNN Block for first sensor type self.conv_block_acc = Sequential( Conv1d(in_channels=3, out_channels=self.out_features32, kernel_size = self.K24, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features32), Conv1d(in_channels=self.out_features32, out_channels=self.out_features64, kernel_size = self.K16, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features64), Conv1d(in_channels=self.out_features64, out_channels=self.out_features96, kernel_size = self.K8, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features96) ) # CNN Block for second sensor type self.conv_block_eog = Sequential( Conv1d(in_channels=2, out_channels=self.out_features32, kernel_size = self.K24, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features32), Conv1d(in_channels=self.out_features32, out_channels=self.out_features64, kernel_size = self.K16, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features64), Conv1d(in_channels=self.out_features64, out_channels=self.out_features96, kernel_size = self.K8, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features96) ) # CNN Block for third sensor type self.conv_block_gyro = Sequential( Conv1d(in_channels=3, out_channels=self.out_features32, kernel_size = self.K24, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features32), Conv1d(in_channels=self.out_features32, out_channels=self.out_features64, kernel_size = self.K16, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features64), Conv1d(in_channels=self.out_features64, out_channels=self.out_features96, kernel_size = self.K8, padding = 1), nn.ReLU(), BatchNorm1d(self.out_features96) ) # CNN for concatenating all sensor types self.conv_block2 = Sequential( Conv1d(in_channels=self.out_features96, out_channels=self.out_features128, kernel_size = self.K4 , padding = 1), nn.ReLU(), BatchNorm1d(self.out_features128) ) # Global Maxpooling Layer self.global_max_pool = nn.MaxPool1d(kernel_size = self.K2 , stride = 2) # Droput Layer self.dropout = Dropout(p=dropout_p) # Classifer for first sensor and third type (because they have the same amount of classes self.classifer_acc_gyro = Sequential( nn.LazyLinear(512), #nn.Linear(1534,512), nn.ReLU(), nn.Linear(512, 256), nn.ReLU(), nn.Linear(256, 9) ) # Classifer for second sensor type self.classifer_eog = Sequential( nn.LazyLinear(512), #nn.Linear(1534,512), nn.ReLU(), nn.Linear(512,256), nn.ReLU(), nn.Linear(256, 8) ) self.softmax_layer = nn.LogSoftmax(dim=1)def forward(self, x_eog, x_acc, x_gyro):
“”"
x = All sensors
x_eog = EOG
x_acc = ACC
x_gyro = GYRO
“”"x_eog = torch.reshape(x_eog, (x_eog.shape[0], x_eog.shape[2], x_eog.shape[1] )) x_acc = torch.reshape(x_acc, (x_acc.shape[0], x_acc.shape[2], x_acc.shape[1] )) x_gyro = torch.reshape(x_gyro, (x_gyro.shape[0], x_gyro.shape[2], x_gyro.shape[1] )) # Feeding each sensor to their corresponding CNN block x_eog = self.conv_block_eog(x_eog) x_acc = self.conv_block_acc(x_acc) x_gyro = self.conv_block_gyro(x_gyro) # Concatenating all sensor types along the batch size x = torch.cat((x_eog, x_acc, x_gyro), dim = 0) # Feeding concatenated sensors to CNN block 2 x = self.conv_block2(x) x = self.global_max_pool(x) x = self.dropout(x) # splitting of the sensors again, along the batch size x_eog, x_acc, x_gyro = torch.split(x, (x.shape[0]//3), dim=0) #Classifer first sensor type x_acc = self.classifer_acc_gyro(x_acc) #x_acc = self.softmax_layer(x_acc) #Classifer second sensor type x_eog = self.classifer_eog(x_eog) #x_eog = self.softmax_layer(x_eog) #Classifer third sensor type x_gyro = self.classifer_acc_gyro(x_gyro) #x_gyro = self.softmax_layer(x_gyro) #Use Softmax x_eog = self.softmax_layer(x_eog) x_acc = self.softmax_layer(x_acc) x_gyro = self.softmax_layer(x_gyro) return x_eog[:, -1], x_acc[:, -1], x_gyro[:, -1]
for epoch in tqdm.tqdm(range(1, epochs+1)):
— TRAIN AND EVALUATE ON TRAINING SET --------------------------
model.train() train_loss_eog, train_loss_acc, train_loss_gyro = 0.0, 0.0, 0.0 num_train_correct_eog, num_train_correct_acc, num_train_correct_gyro = 0, 0, 0 num_train_examples_eog,num_train_examples_acc, num_train_examples_gyro = 0,0, 0 for batch in train_dataloader: optimizer.zero_grad() # Splitting of the data, according to their sensor types inputs_eog, targets_eog = batch[0][0], batch[0][1] inputs_acc, targets_acc = batch[1][0], batch[1][1] inputs_gyro, targets_gyro = batch[2][0], batch[2][1] # Calculating the class_weights class_weights_eog = calculate_class_weight(targets_eog, sensortype='EOG') class_weights_acc = calculate_class_weight(targets_acc, sensortype='ACC') class_weights_gyro = calculate_class_weight(targets_gyro, sensortype='GYRO') # Feed everything to GPU class_weights_eog,class_weights_acc, class_weights_gyro = class_weights_eog.to(device), class_weights_acc.to(device),class_weights_gyro.to(device) inputs_eog, targets_eog = inputs_eog.to(device), targets_eog.to(device) inputs_acc, targets_acc = inputs_acc.to(device), targets_acc.to(device) inputs_gyro, targets_gyro = inputs_gyro.to(device), targets_gyro.to(device) # Feeding the inputs to the model predictions_eog, predictions_acc, predictions_gyro = model(x_eog = inputs_eog, x_acc = inputs_acc, x_gyro = inputs_gyro) #Calculating the loss loss_fn_eog = NLLLoss(weight = class_weights_eog, reduction='mean') loss_fn_acc = NLLLoss(weight = class_weights_acc, reduction='mean') loss_fn_gyro = NLLLoss(weight = class_weights_gyro, reduction='mean') # Combine their loss total_loss = loss_eog+loss_acc+loss_gyro total_loss.backward() optimizer.step() train_loss_eog += loss_eog.data.item() * inputs_eog.size(0) train_loss_acc += loss_acc.data.item() * inputs_acc.size(0) train_loss_gyro += loss_gyro.data.item() * inputs_gyro.size(0) num_train_correct_eog += (torch.max(predictions_eog, 1)[1] == targets_eog).sum().item() num_train_examples_eog += inputs_eog.shape[0] num_train_correct_acc += (torch.max(predictions_acc, 1)[1] == targets_acc).sum().item() num_train_examples_acc += inputs_acc.shape[0] num_train_correct_gyro += (torch.max(predictions_gyro, 1)[1] == targets_gyro).sum().item() num_train_examples_gyro += inputs_gyro.shape[0] train_acc_eog = num_train_correct_eog / num_train_examples_eog train_loss_eog = train_loss_eog / len(train_dataloader.dataset) train_acc_acc = num_train_correct_acc / num_train_examples_acc train_loss_acc = train_loss_acc / len(train_dataloader.dataset) train_acc_gyro = num_train_correct_gyro / num_train_examples_gyro train_loss_gyro = train_loss_gyro / len(train_dataloader.dataset)