My model is given by:
class MyNetQ(nn.Module):
def __init__(self):
super(MyNetQ, self).__init__()
self.myp=0.5
self.flatten = nn.Flatten()
self.linear_LeakyReLU_stack = nn.Sequential(
nn.Linear(8*68, 8*60),
nn.LeakyReLU(),
nn.Dropout(p=self.myp),
nn.Linear(8*60, 8*50),
nn.LeakyReLU(),
nn.Dropout(p=self.myp),
nn.Linear(8*50, 8*40),
nn.LeakyReLU(),
nn.Dropout(p=self.myp),
nn.Linear(8*40, 8*30),
nn.LeakyReLU(),
nn.Dropout(p=self.myp),
nn.Linear(8*30, 8*20),
nn.LeakyReLU(),
nn.Dropout(p=self.myp),
nn.Linear(8*20, 8*15),
nn.LeakyReLU(),
nn.Linear(8*15, 11)
)
def forward(self, x):
x = self.flatten(x)
out = self.linear_LeakyReLU_stack(x)
return out
During the training process, the soft cross entropy loss exhibits huge spikes after seemingly having made good progress:
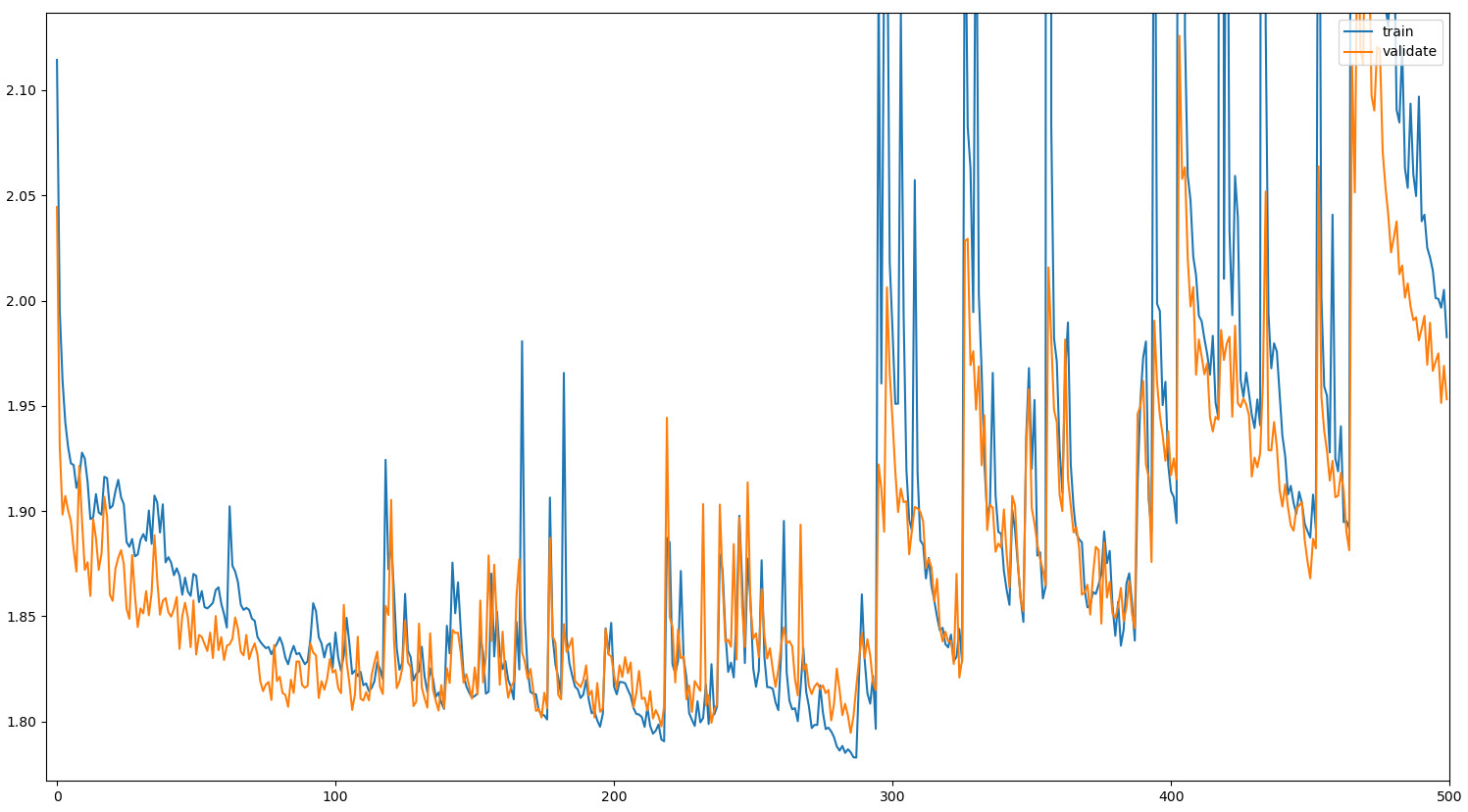
What could be the reason for this behavior? Is there any way I could make the training process more stable?