I’m trying to build a speech-to-text system my data is (4 - 10 seconds audio wave files) and their transcription (preprocessing steps are char-level encoding to transcription and extract mel-Spectrograms from audio files).
this is my model architecture is ( a 3 conv1d layers with positional encoding to the audio file - embedding and positional encoding to encoded transcription and then use those as input to transformer model and lastly a dense layer)
the loss function is cross entropy and optimizer is Adam.
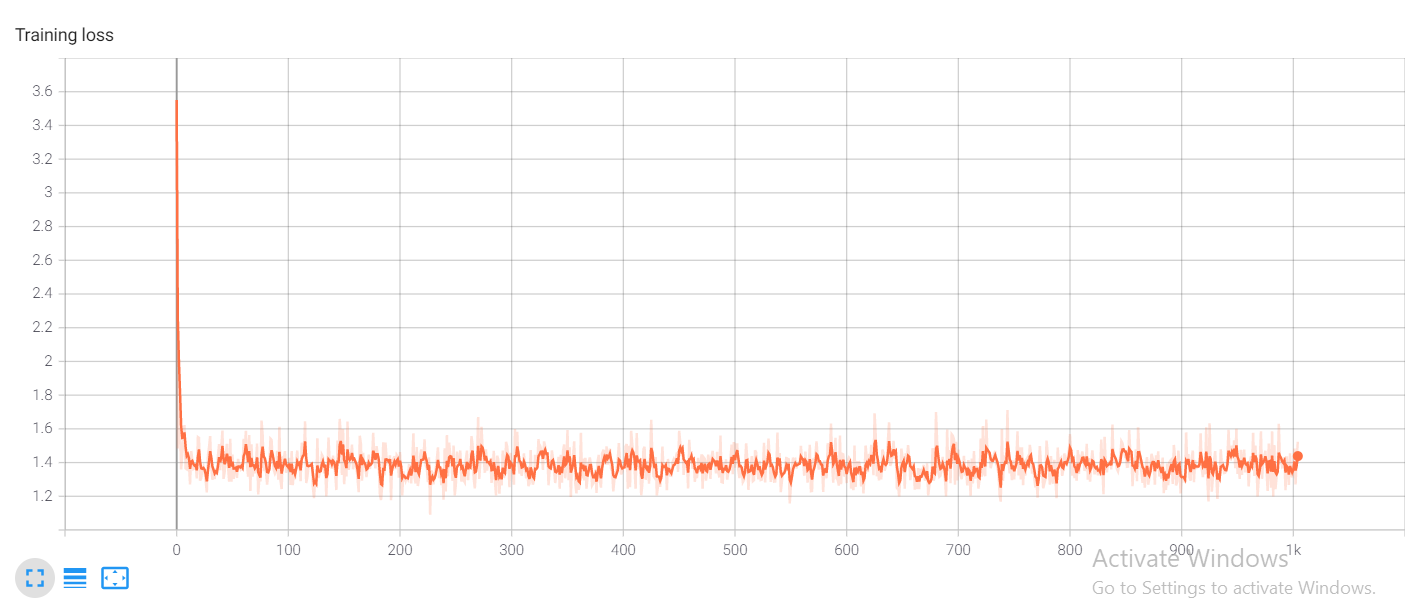
the problem is that the loss is always stuck at some point it starts around 3.8 (I have 46 classes) and after some batches it decreases to (e.g. 2,8) and stuck their. it bounces around that value and never decrease again.
I tried changing parameters of the model, I’ve changed the optimizer and learning rate always result the same problem.
I don’t understand what I’m doing wrong