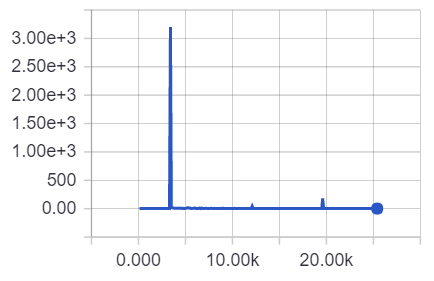
Hi, I came across a problem when using Adam optimizer. At the start of the training, the loss decreases as expected. But after 3300 iterations, the loss suddenly explodes to a very large number(~1e3). I tried several times but the same problem occurs. How to solve this issue? Thanks!
Did you restart at 3300’th iteration? Or did you run it all along?. I think you need to give more info. what is the problem you are working with? What’s the step-size?
In anycase, the problem with Adam is that it uses moving average in the denominator term. So if the gradients get really small and the whole of denominator will be small. Since the gradients are already small, the denominator results in blowup thus pushing you very far away hence huge loss. You may have a look at https://openreview.net/forum?id=ryQu7f-RZ . I think there are many recent methods which avert this problem including AMSGrad (in the earlier mentioned paper), Hyper-gradient descent (for Adam) etc. Also look for comments in the openreview forum, there seems to be further discussion on this issue. Unfortunately i do not know of any pytorch implementation of these algorithms.
Thanks a lot for your detailed reply, Munkiti. I run my training all along without any restart. The learning rate for Adam is 1e-3. The network is typical resnet structure.
I will check whether the problem comes from the small denominator with Adam. I will post it when I find a solution.
As suggestion, I replace the Adam optimizer with AMSGrad. The problem is solved^^ It indeed comes from the stabilization issue of the Adam itself.
In implementation, I reinstall my pytorch from source and in version 4.0, I can simply use AMSGrad with: optimizer = optim.Adam(model.parameters(), lr=0.001, eps=1e-3, amsgrad=True)
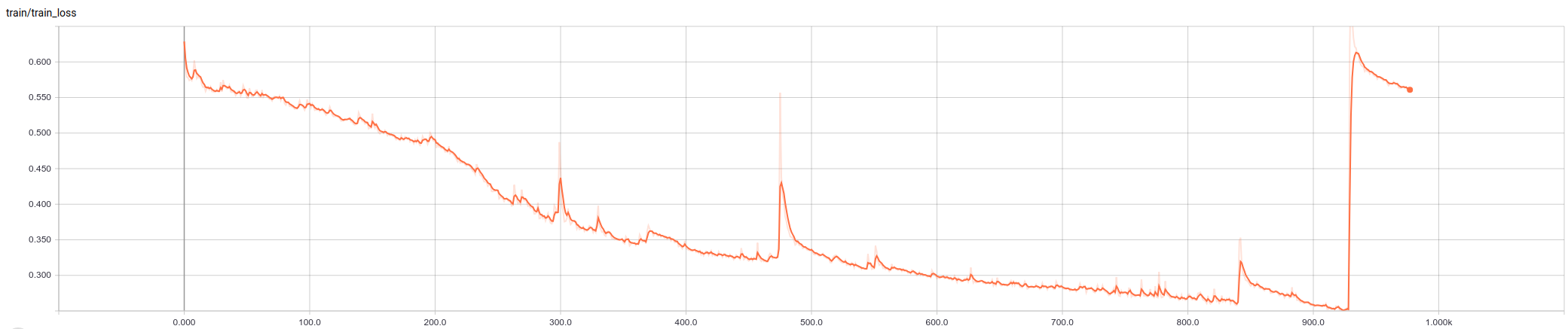
While AMSGrad really improves the training loss curve and it seems to progress for a longer number of epochs, but after certain number of epochs, even AMSGrad tends to increase training loss
Well, kind of. As the training performance improves, I linearly reduce the learning rate (learning rate at perfect performance is 1/10th the original LR). This significantly combats this tendency to overshoot.