Hi,
I am working on a classification problem using a typical L2 loss. Is there a proper way of adding a loss term which is a function of gradients? For example, lets say I want the gradients of certain layer to sum up to 1:
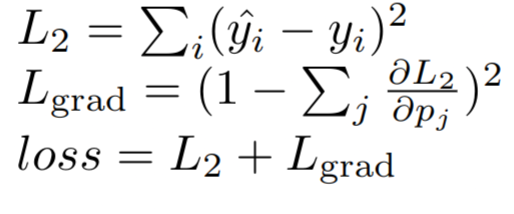
What would be the proper way of implementing that in pytorch?
x1 = layer1(inputs)
x2 = layer2(x1)
x2.retain_grads()
preds = layer3(x2)
loss_l2 = l2(preds, labels)
loss_l2.backward() # get the gradients
loss_grads = (1-x2.grads.sum())**2
loss = loss_l2 + loss_grads
loss.backward()
optimizer.step()
Would that be ok? Or it wouldn’t because we are taking second derivative here and one should rather provide gradients of loss_grads manually?