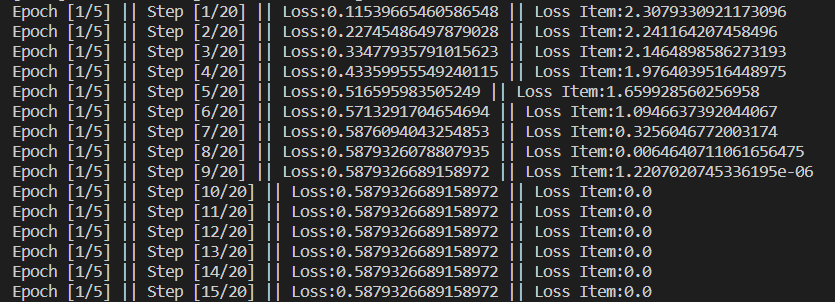
Hey,
I am using PyTorch for multiclass classification. I’ve one hot encoded the labels. On running the model I am getting train and validation losses and accuracies for first epoch but for all the next epochs their value is coming out to be 0. Also I’m not using a dataloader, instead I’m using a function of my own to load the data in batches. I’m a beginner please guide me.
def train_model(model, criterion, optimizer, num_epochs=10):
for epoch in range(num_epochs):
print(‘Epoch {}/{}’.format(epoch+1, num_epochs))
print(’-’ * 10)
for phase in ['train', 'val']:
if phase == 'train':
model.train()
else:
model.eval()
running_loss = 0.0
running_corrects = 0.0
for i,(inputs, labels) in enumerate(dataloaders[phase]):
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
_,lab1 = torch.max(labels.data, 1)
loss = criterion(outputs, labels)
if phase == 'train':
optimizer.zero_grad()
loss.backward()
optimizer.step()
_, preds = torch.max(outputs, 1)
running_loss += loss.item() * inputs.size(0)
running_corrects += torch.sum(preds == lab1)
epoch_loss = running_loss / dataset_sizes[phase]
epoch_acc = float(running_corrects/dataset_sizes[phase])
print('{} loss: {:.4f}, acc: {:.4f}'.format(phase,
epoch_loss,
epoch_acc))
return model
device = torch.device("cpu")
model_ft = models.resnet50(pretrained=True).to(device)
for param in model_ft.parameters():
param.requires_grad = False
model_ft.fc = nn.Sequential(
nn.Linear(2048, 1000),
nn.ReLU(inplace=True),
nn.Linear(1000, 136)).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_ft.fc.parameters(), lr=0.001)
model_ft = train_model(model_ft, criterion, optimizer, num_epochs=10)