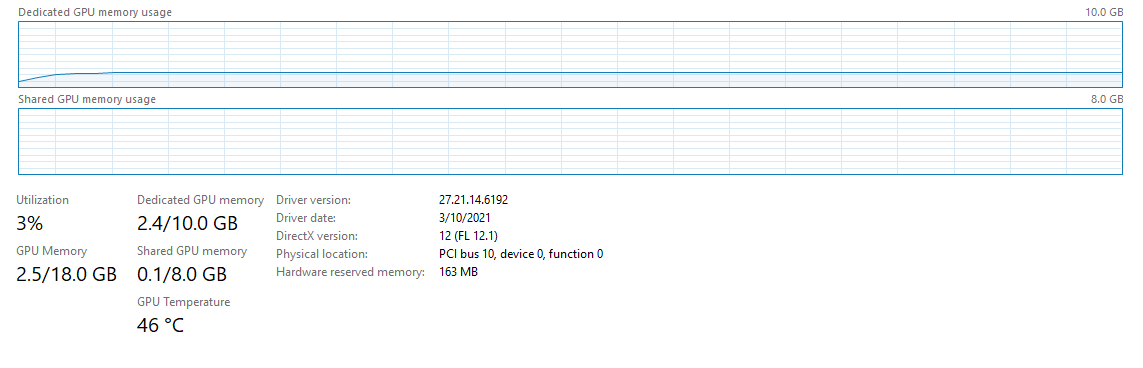
Hi! I am training a Convnet to classify CIFAR10 images on RTX 3080 GPU. For some reason, when I look at the GPU usage in task manager, it shows 3% GPU usage as shown in the image.
The model is as follows
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet,self).__init__()
self.conv1 = nn.Conv2d(in_channels=3,out_channels=8,stride=1,kernel_size=(3,3),padding=1)
self.conv2 = nn.Conv2d(in_channels=8,out_channels=32,kernel_size=(3,3),padding=1,stride=1)
self.conv3 = nn.Conv2d(in_channels=32,out_channels=64,kernel_size=(3,3),padding=1,stride=1)
self.conv4 = nn.Conv2d(in_channels=64,out_channels=128,kernel_size=(3,3),padding=1,stride=1)
self.conv5 = nn.Conv2d(in_channels=128,out_channels=256,kernel_size=(3,3),stride=1)
self.fc1 = nn.Linear(in_features=6*6*256,out_features=256)
self.fc2 = nn.Linear(in_features=256,out_features=128)
self.fc3 = nn.Linear(in_features=128,out_features=64)
self.fc4 = nn.Linear(in_features=64,out_features=10)
self.max_pool = nn.MaxPool2d(kernel_size=(2,2),stride=2)
self.dropout = nn.Dropout2d(p=0.5)
def forward(self,x,targets):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool(x)
x = self.conv3(x)
x = F.relu(x)
x = self.dropout(x)
x = self.conv4(x)
x = F.relu(x)
x = self.max_pool(x)
x = self.conv5(x)
x = F.relu(x)
x = self.dropout(x)
x = x.view(-1,6*6*256)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
x = F.relu(x)
x = self.fc3(x)
x = F.relu(x)
logits = self.fc4(x)
loss = None
if targets is not None:
loss = F.cross_entropy(logits,targets)
return logits,loss
def configure_optimizers(self,config):
optimizer = optim.Adam(self.parameters(),lr=config.lr,betas=config.betas,weight_decay=config.weight_decay)
return optimizer
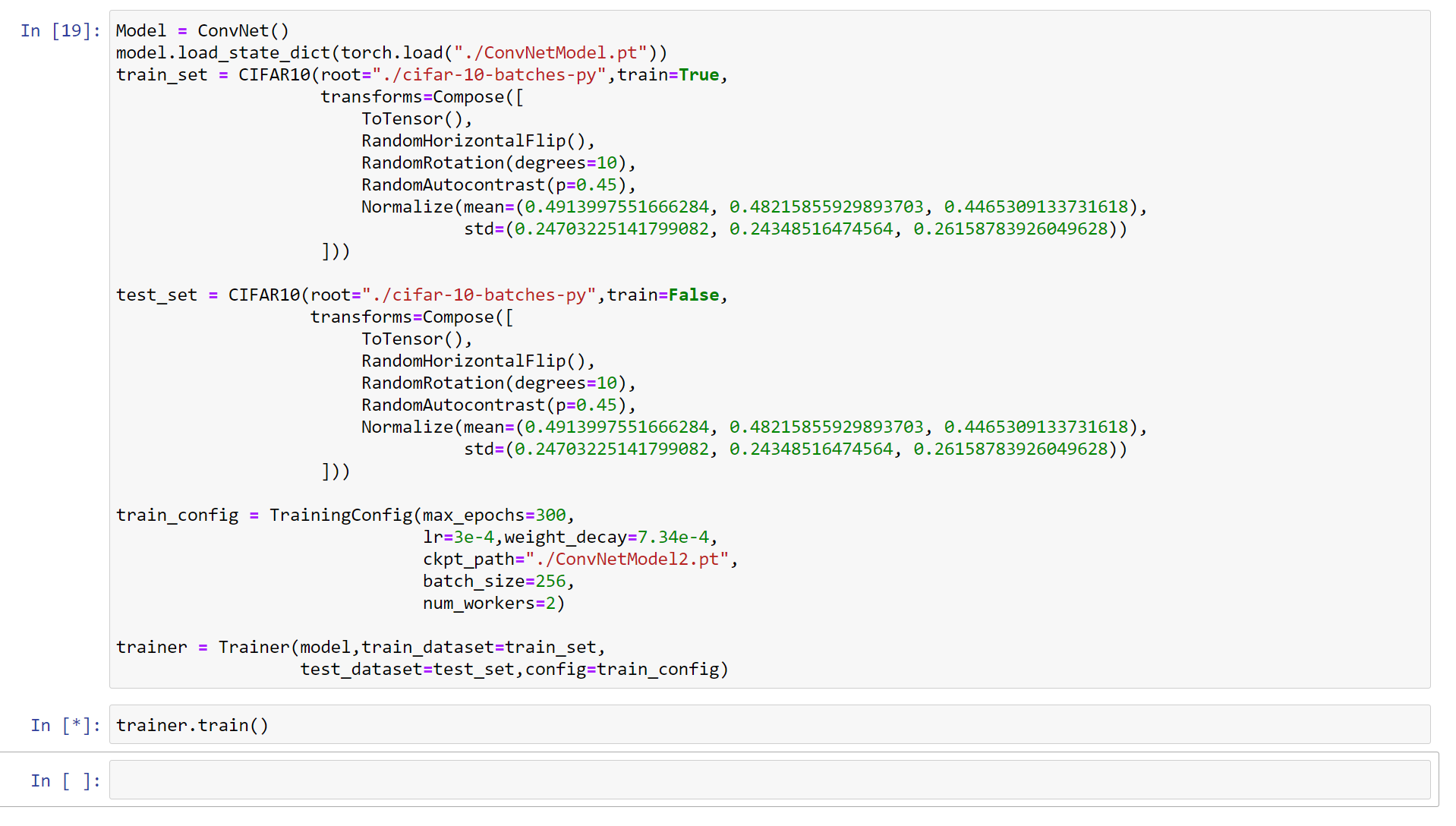
Training Configurations are as follows:
Epochs : 300
Batch Size : 64
Weight Decay : 7.34e-4
Learning Rate : 3e-4
Optimizer : Adam
Also I am running several transforms such as Normalization, RandomRotation, RandomHorizontalFlips.
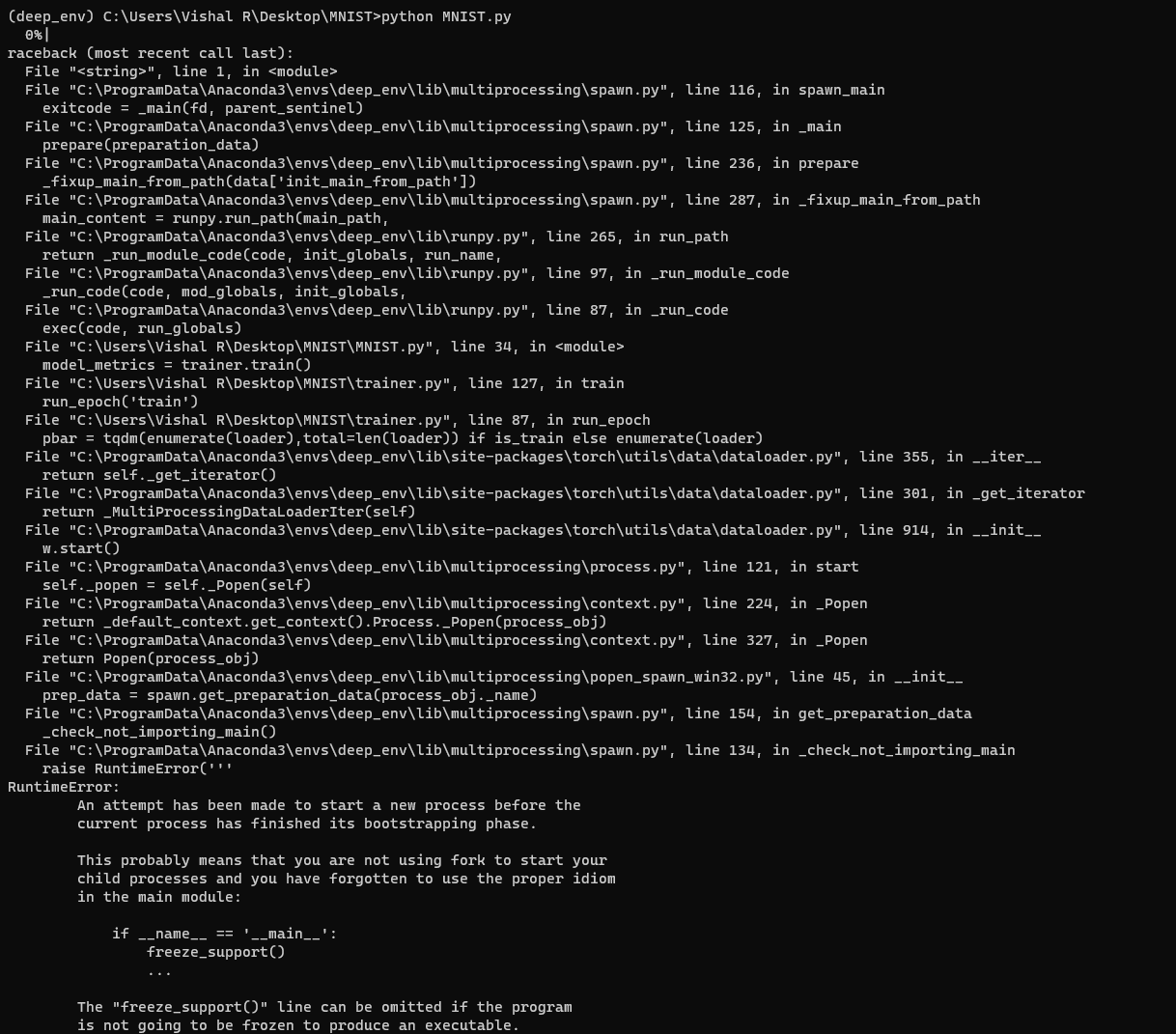
Also I have another bug. When I change the number of workers in DataLoader, the training just begin at all. In jupyter notebook, it shows that cell is being executed but no output is shown. So I am forced to run with num_workers=0. Anything above 0 breaks for some reason.