Hey Everyone,
I am working on finding the best learning rate (lr) and weight decay (wd) values for my networks and applied the methods described in [1, 2] to find the best lr to help convergence,
I have let the algorithm run for different wd values but are now confused which one to pick:
Here are 2 example plots of different models:
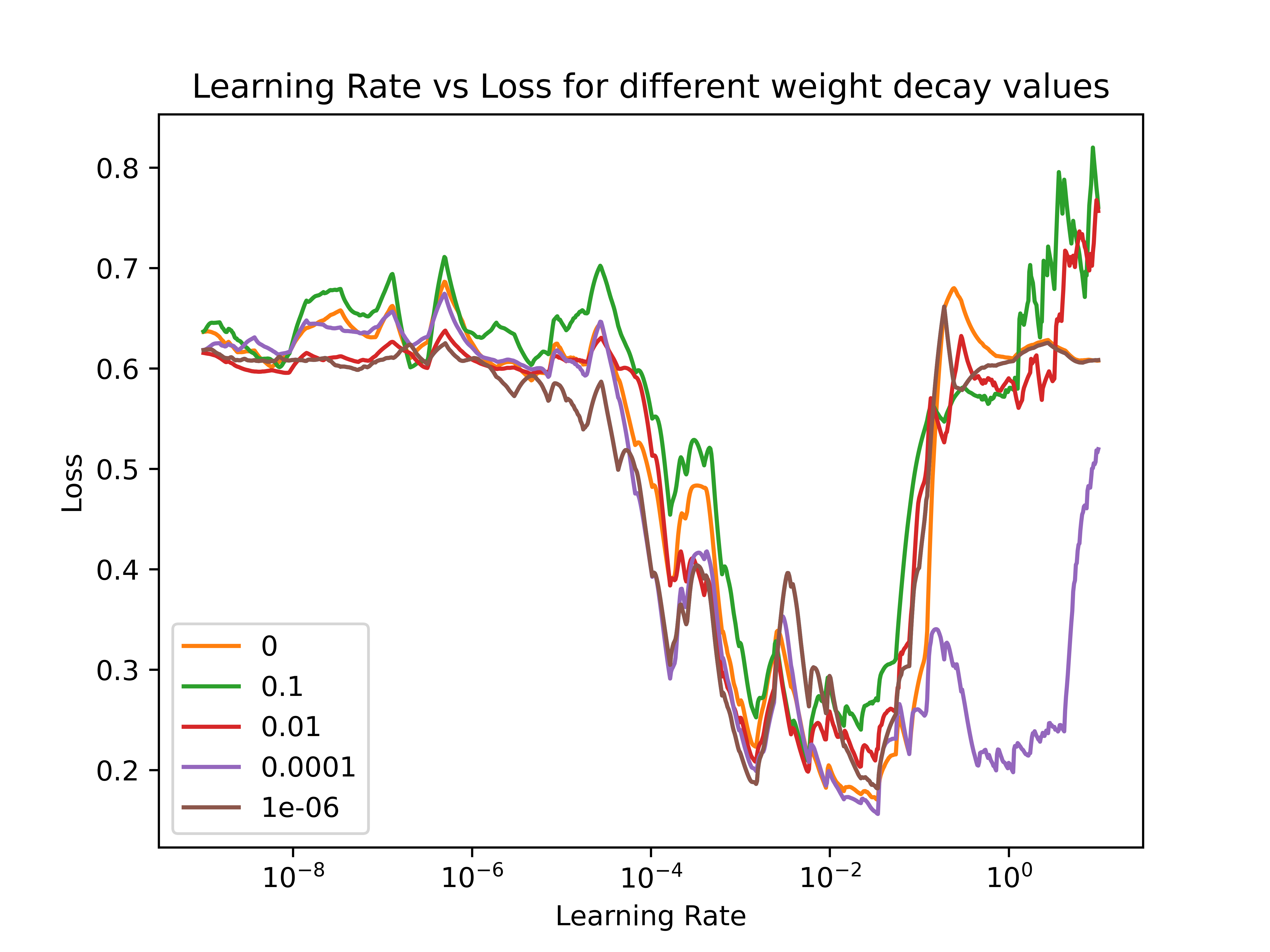
img 2
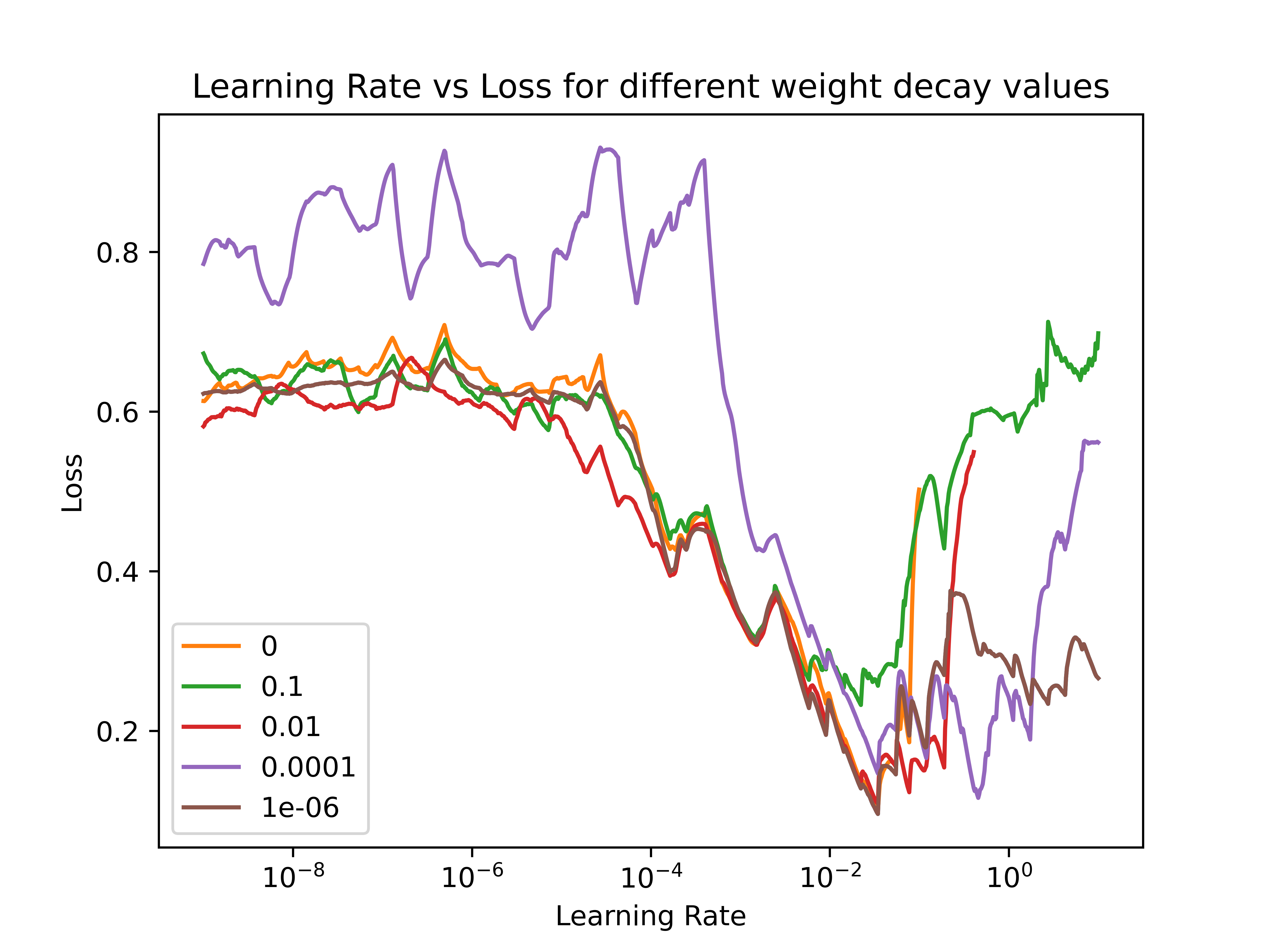
(the algorithm stops early if it detects divergence, therefore some lines are cut of earlier)
what should i consider when picking the lr for the different WD values.
Is it good if the divergence happens at a higher lr (e.g. purple in img 1)?
Is a shallow or a steep drop (around 1e-4 to 1e-1 in img 2) good?
In generell i know i should pick my max lr to be around the lowest point but i struggle to interpret the rest of the plots.
Any help is much appreciated ![]()
Cheers, Sven
[1] [1803.09820] A disciplined approach to neural network hyper-parameters: Part 1 -- learning rate, batch size, momentum, and weight decay
[2] [1506.01186] Cyclical Learning Rates for Training Neural Networks