consider the case of machine translation using encoder decoder architecture. Consider the case when nn.Lstm is used as encoder as well as decoder. Assume the number of nn.LstmCell in both is 5.
In case of encoder, during the forward propagation, we send a batch of sentences, and for each sentence, word_i is passed as input to LstmCell_i. This Lstm finally returns the hidden state to decoder.
In case of decoder, for each sentence, a loop is created, whose length is the length of sentence we want to generate. Each word is generated by passing previous word (and hidden state) through Lstm. The lstm with 5 layer is used to encode a sentence in encoder, while it is used to generate a word in decoder. Does this mean, while decoding, each word has to pass through each 5 LstmCell and the output of final cell predicts the word ?
Can you give a little more detail ?
and so, the final prediction for each word comes from the output of last LstmCell ? And does this mean images like this about Lstm are completely misleading ? (which show that each word is fed to each LstmCell) ?
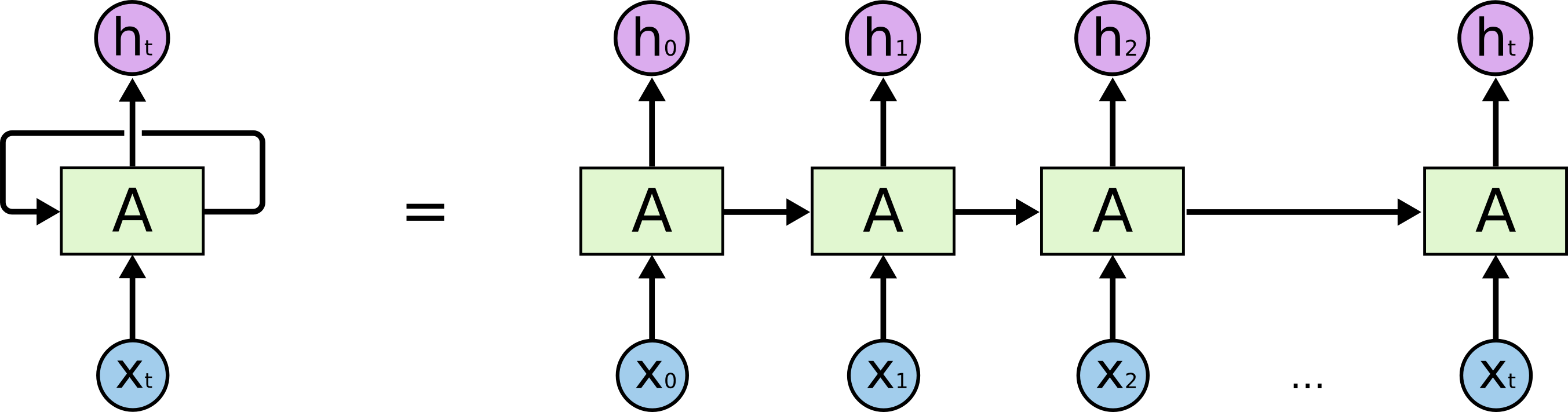
That’s probably your misunderstanding. There is not a list of cells, but only cell that is recurrently used until a stop condiation is met – for the encoder, when the last word/item in the sequences as been processed.
The output of the cell at time i is used as input of the cell at the next time step i+1.
The illustrations you’ve linked just show the “unrolled” network to better visualize the sequential nature of the processing. All the cells are indeed the same cell. See the image below: both representations show the same network – left with the recurrent connection and right unrolled to better see how the sequence is processed.