I am implementing LSTM autoencoder which is similar to the paper by Srivastava et. al (‘Unsupervised Learning of Video Representations using LSTMs’).
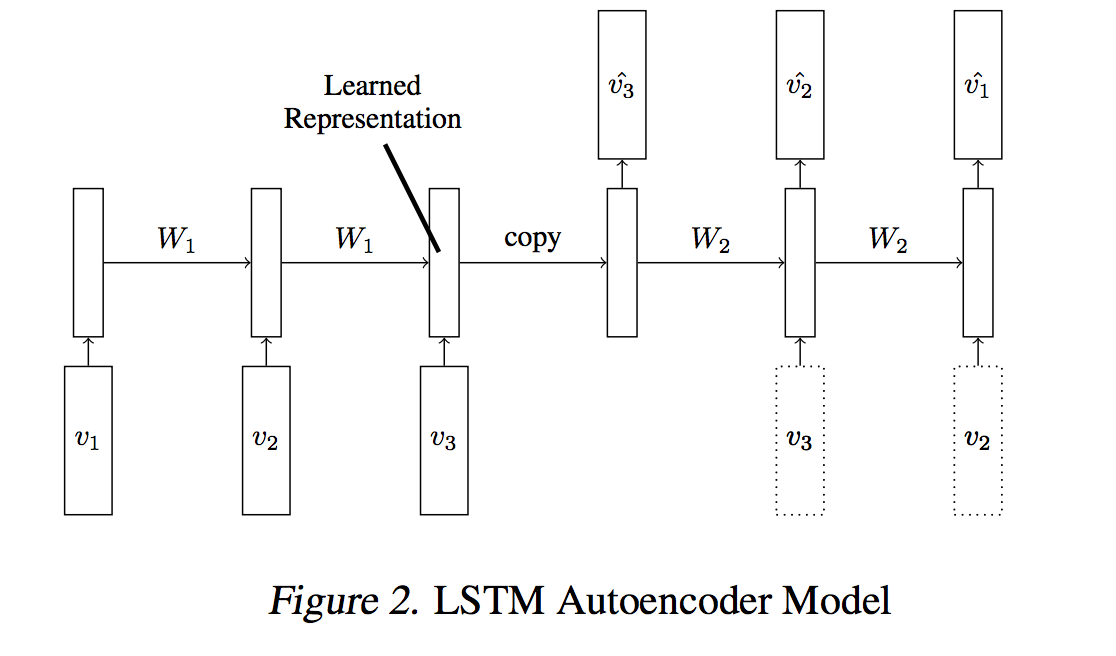
In the above figure, the weights in the LSTM encoder is copied to those of the LSTM decoder.
To implement this, is the encoder weights cloned to the decoder ?
More specifically, is the snippet blow correct ?
class Sequence(nn.Module):
def __init__(self):
super(Sequence, self).__init__()
self.lstm_enc = nn.LSTMCell(1, hidden_size)
self.fc_enc = nn.Linear(hidden_size,1)
self.lstm_dec = nn.LSTMCell(1, hidden_size)
self.fc_dec = nn.Linear(hidden_size,1)
def forward(self, input, input_r):
outputs = []
h_t_enc = Variable(torch.zeros(input.size(0), hidden_size).cuda(), requires_grad=False)
c_t_enc = Variable(torch.zeros(input.size(0), hidden_size).cuda(), requires_grad=False)
# enc
for i, input_t in enumerate(input.chunk(input.size(1), dim=1)):
h_t_enc, c_t_enc = self.lstm_enc(input_t, (h_t_enc, c_t_enc))
output = self.fc_enc(c_t3_enc)
#dec
h_t_dec = h_t_enc.clone()
c_t_dec = c_t_enc.clone()
outputs += [output]
# note that input_r is the time-reverse version of input
for i, input_t in enumerate(input_r.chunk(input_r.size(1), dim=1)):
if i != input_r.size(1)-1:
h_t_dec, c_t_dec = self.lstm1_dec(input_t, (h_t_dec, c_t_dec))
output = self.fc_dec(c_t_dec)
outputs += [output]
outputs = torch.stack(outputs, 1).squeeze(2)
return outputs
 Thanks a lot.
Thanks a lot.