Here is my model:
Encoder:
class Encoder(nn.Module):
def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(input_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.dropout = nn.Dropout(dropout)
self.layer_norm_1 = nn.LayerNorm(emb_dim)
def forward(self, src):
embedded = self.embedding(src) # removed dropout after
outputs, (hidden, cell) = self.rnn(embedded)
return hidden, cell
Decoder:
class Decoder(nn.Module):
def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):
super().__init__()
self.output_dim = output_dim
self.hid_dim = hid_dim
self.n_layers = n_layers
self.embedding = nn.Embedding(output_dim, emb_dim)
self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout = dropout)
self.fc_out = nn.Linear(hid_dim, output_dim)
self.dropout = nn.Dropout(dropout)
self.layer_norm_1 = nn.LayerNorm(emb_dim)
def forward(self, input, hidden, cell):
input = input.unsqueeze(0)
embedded = self.embedding(input) # removed dropout after embedding layer
output, (hidden, cell) = self.rnn(embedded, (hidden, cell))
prediction = self.fc_out(output.squeeze(0))
return prediction, hidden, cell
Training:
def train(encoder, decoder, src, trg, optimizer, loss, teacher_forcing_ratio = 0.5):
encoder.train()
decoder.train()
for src, trg in zip(src, trg):
optimizer.zero_grad()
src = src.transpose(-1, 0)
trg = trg.transpose(-1, 0)
src = src.to(device)
trg = trg.to(device)
batch_size = trg.shape[1]
trg_len = trg.shape[0]
trg_vocab_size = decoder.output_dim
outputs = torch.zeros(trg_len, batch_size, trg_vocab_size).to(device) # N x batch x vocab_size
hidden, cell = encoder(src) # src = N x batch_size
input = trg[0, :]
for t in range(1, trg_len):
output_, hidden, cell = decoder(input, hidden, cell)
outputs[t] = output_
teacher_force = random.random() < teacher_forcing_ratio
top1 = output_.argmax(1)
input = trg[t] if teacher_force else top1
outputs = outputs[1:].reshape(-1, outputs.shape[2]) # list of words in the entire batch and it's predicted output
trg = trg[1:].reshape(-1)
l = loss(outputs, trg)
l.backward()
torch.nn.utils.clip_grad_norm_(encoder.parameters(), 1)
torch.nn.utils.clip_grad_norm_(decoder.parameters(), 1)
optimizer.step()
return l.detach().cpu().numpy()
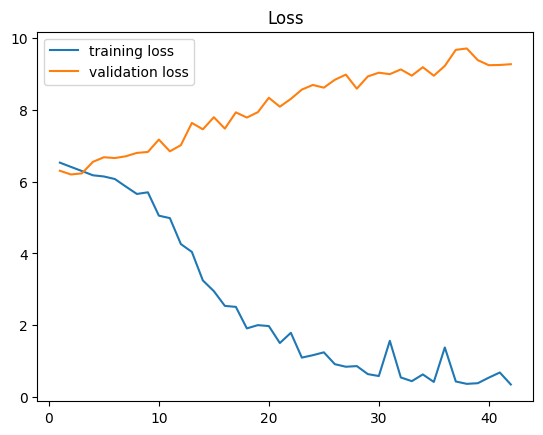
I tried various things such as :
- used dropout and keeping dropout=1 also gives the same problem
- increased training data from 10K to 20K
- decreased 2 layers LSTM to 1
- added weight decay (1e-4)
- shuffled data and gradient clipping
Any help would be appreciated.