After a lot of struggling, I was able to implement a version of an autoencoder that uses an LSTM’s final hidden state as the encoding.
It trains with a pretty loss curve:
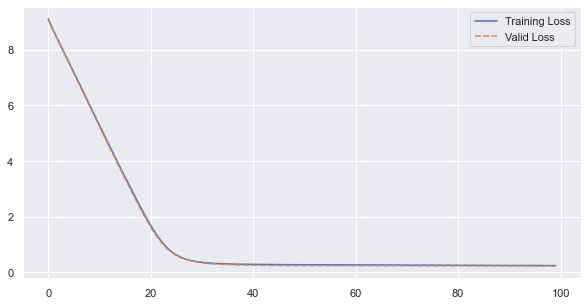
but the decoder just outputs the average of the sequence (after a warm-up):
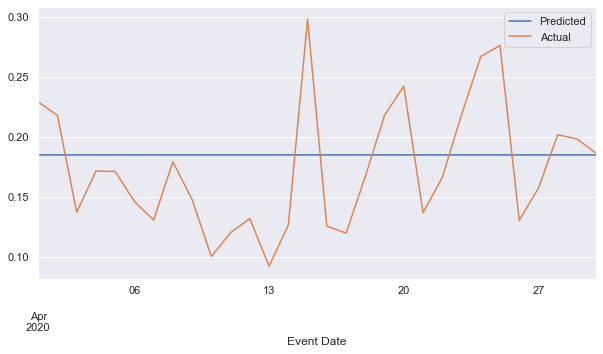
I’m wondering what could be causing this kind of behavior in an autoencoder?
Encoder Class:
class SeqEncoderLSTM(nn.Module):
def __init__(self, n_features, latent_size):
super(SeqEncoderLSTM, self).__init__()
self.lstm = nn.LSTM(
n_features,
latent_size,
batch_first=True)
def forward(self, x):
_, hs = self.lstm(x)
return hs
Decoder class:
class SeqDecoderLSTM(nn.Module):
def __init__(self, emb_size, n_features):
super(SeqDecoderLSTM, self).__init__()
self.cell = nn.LSTMCell(n_features, emb_size)
self.dense = nn.Linear(emb_size, n_features)
def forward(self, hs_0, seq_len):
# add each point to the sequence as it's reconstructed
x = torch.tensor([])
# Final hidden and cell state from encoder
hs_i, cs_i = hs_0
# reconstruct first (last) element
x_i = self.dense(hs_i)
x = torch.cat([x, x_i])
# reconstruct remaining elements
for i in range(1, seq_len):
hs_i, cs_i = self.cell(x_i, (hs_i, cs_i))
x_i = self.dense(hs_i)
x = torch.cat([x, x_i])
return x
Bringing the two together:
class LSTMEncoderDecoder(nn.Module):
def __init__(self, n_features, emb_size):
super(LSTMEncoderDecoder, self).__init__()
self.n_features = n_features
self.hidden_size = emb_size
self.encoder = SeqEncoderLSTM(n_features, emb_size)
self.decoder = SeqDecoderLSTM(emb_size, n_features)
def forward(self, x):
seq_len = x.shape[1]
hs = self.encoder(x)
hs = tuple([h.squeeze(0) for h in hs])
out = self.decoder(hs, seq_len)
return out.unsqueeze(0)