I train a simple LSTM to do classifier on MNIST in LSTM, whether I use batch_first, I get the different result, here is my code
import torch
from torch import nn, optim
from torch.autograd import Variable
from torch.utils.data import DataLoader
from torchvision import transforms
from torchvision import datasets
batch_size = 100
learning_rate = 1e-2
num_epoches = 20
train_dataset = datasets.MNIST(root='./data', train=True,
transform=transforms.ToTensor(),
download=True)
test_dataset = datasets.MNIST(root='./data', train=False,
transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=False)
class Rnn(nn.Module):
def __init__(self, in_dim, hidden_dim, n_layer, n_class):
super(Rnn, self).__init__()
self.n_layer = n_layer
self.hidden_dim = hidden_dim
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer)
# batch_first=True)
self.classifier = nn.Linear(hidden_dim, n_class)
def forward(self, x):
# h0 = Variable(torch.zeros(self.n_layer, x.size(1),
# self.hidden_dim)).cuda()
# c0 = Variable(torch.zeros(self.n_layer, x.size(1),
# self.hidden_dim)).cuda()
out, _ = self.lstm(x)
out = out[-1, :, :]
out = self.classifier(out)
return out
model = Rnn(28, 128, 2, 10)
use_gpu = torch.cuda.is_available()
if use_gpu:
model = model.cuda()
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(num_epoches):
print('epoch {}'.format(epoch+1))
print('*'*10)
running_loss = 0.0
running_acc = 0.0
for i, data in enumerate(train_loader, 1):
img, label = data
b, c, h, w = img.size()
assert c == 1, 'channel must be 1'
img = img.view(w, b, h)
if use_gpu:
img = Variable(img).cuda()
label = Variable(label).cuda()
out = model(img)
loss = criterion(out, label)
running_loss += loss.data[0] * label.size(0)
_, pred = torch.max(out, 1)
num_correct = (pred == label).sum()
running_acc += num_correct.data[0]
optimizer.zero_grad()
loss.backward()
optimizer.step()
if i % 300 == 0:
print('[{}/{}] Loss: {:.6f}, Acc: {:.6f}'.format(
epoch+1, num_epoches,
running_loss/(batch_size*i),
running_acc/(batch_size*i)
))
print('Finish {} epoch, Loss: {:.6f}, Acc: {:.6f}'.format(
epoch+1,
running_loss/(len(train_dataset)),
running_acc/(len(train_dataset))
))
here is the first epoch result

but if I use batch_first in LSTM, I get the different result, the different in code is below
self.lstm = nn.LSTM(in_dim, hidden_dim, n_layer, batch_first=True)
out = out[:, -1, :]
img = img.view(b, w, h)
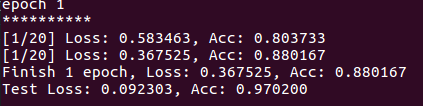
Can anyone tell me reason? Thank u guys.