Hi everyone,
i’m using an LSTM to process some sequential data. Those data come from different sources, suppose that we have N of them, and have a fixed length, say M. I’m using DDP to process those data in parallel with N training processes, each of them proessing one single sequence. I cannot use BPTT, so i have to process all the sequence all way down to the end.
A simple reproducible script is the following:
import argparse
import os
import socket
import time
from contextlib import closing
from multiprocessing.connection import Connection, Pipe
from typing import List, Tuple
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
device = "cpu"
def find_free_port():
with closing(socket.socket(socket.AF_INET, socket.SOCK_STREAM)) as s:
s.bind(("", 0))
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
return s.getsockname()[1]
def init_process(rank, world_size, ddp_free_port, recv, rnn_type):
"""Initialize the distributed environment."""
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = ddp_free_port
os.environ["RANK"] = str(rank)
os.environ["LOCAL_RANK"] = str(rank)
os.environ["WORLD_SIZE"] = str(world_size)
os.environ["NODE_RANK"] = "0"
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
torch.set_num_threads(1)
torch.set_num_interop_threads(1)
dist.init_process_group("gloo", rank=rank, world_size=world_size)
Worker(recv, rnn_type=rnn_type).train()
class LSTMExtractor(torch.nn.Module):
def __init__(
self,
input_size: int,
fc_out_size: int = 128,
lstm_hidden_size: int = 256,
lstm_num_layers: int = 1,
lstm_batch_first: bool = False,
):
super().__init__()
self.input_size = input_size
self.lstm_hidden_size = lstm_hidden_size
self.lstm_num_layers = lstm_num_layers
self.lstm_batch_first = lstm_batch_first
self.fc = torch.nn.Linear(in_features=input_size, out_features=fc_out_size)
self.lstm = torch.nn.LSTM(
input_size=fc_out_size,
hidden_size=lstm_hidden_size,
num_layers=lstm_num_layers,
batch_first=lstm_batch_first,
)
def forward(
self,
x: torch.Tensor,
state: Tuple[torch.Tensor, torch.Tensor],
) -> Tuple[torch.Tensor, Tuple[torch.Tensor, torch.Tensor]]:
feat = self.fc(x)
self.lstm.flatten_parameters()
out, (hx, cx) = self.lstm(feat, state)
if out.shape[1] == 1:
out = out.view(out.shape[0], -1)
return out, (hx, cx)
class GRUExtractor(torch.nn.Module):
def __init__(
self,
input_size: int,
fc_out_size: int = 128,
gru_hidden_size: int = 256,
gru_num_layers: int = 1,
gru_batch_first: bool = False,
):
super().__init__()
self.input_size = input_size
self.gru_hidden_size = gru_hidden_size
self.gru_num_layers = gru_num_layers
self.gru_batch_first = gru_batch_first
self.fc = torch.nn.Linear(in_features=input_size, out_features=fc_out_size)
self.gru = torch.nn.GRU(
input_size=fc_out_size,
hidden_size=gru_hidden_size,
num_layers=gru_num_layers,
batch_first=gru_batch_first,
)
def forward(
self,
x: torch.Tensor,
state: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
feat = self.fc(x)
self.gru.flatten_parameters()
out, hx = self.gru(feat, state)
if out.shape[1] == 1:
out = out.view(out.shape[0], -1)
return out, hx
class Worker:
def __init__(self, queue, rnn_type="lstm", sequence_length: int = 2048, batch_size: int = 512):
self.rank = dist.get_rank()
self.world_size = dist.get_world_size()
self.queue: Connection = queue
self.rnn_type = rnn_type
if self.rnn_type == "lstm":
self.model = LSTMExtractor(80, fc_out_size=128, lstm_hidden_size=256).to(device)
else:
self.model = GRUExtractor(80, fc_out_size=128, gru_hidden_size=256).to(device)
self.model = DDP(self.model).to(device)
self.optimizer = optim.Adam(self.model.parameters(), lr=0.001)
self.loss_fn = nn.CrossEntropyLoss()
self.sequence_length = sequence_length
self.batch_size = batch_size
def train(self):
data = torch.rand(self.sequence_length, 1, 80) # Fake data
while True:
epoch = self.queue.recv()
if epoch is False:
print(f"Rank-{self.rank} done!")
return
total_loss = 0
if self.rnn_type == "lstm":
(hx, cx) = (torch.zeros(1, 1, 256).to(device), torch.zeros(1, 1, 256).to(device))
tic = time.perf_counter()
for i in range(int(self.sequence_length / self.batch_size)):
batch_data = data[i * self.batch_size : (i + 1) * self.batch_size].to(device)
out, (hx, cx) = self.model(batch_data, (hx, cx))
total_loss += self.loss_fn(out, torch.ones_like(out))
else:
hx = torch.zeros(1, 1, 256).to(device)
tic = time.perf_counter()
for i in range(int(self.sequence_length / self.batch_size)):
batch_data = data[i * self.batch_size : (i + 1) * self.batch_size].to(device)
out, hx = self.model(batch_data, hx)
total_loss += self.loss_fn(out, torch.ones_like(out))
self.optimizer.zero_grad(set_to_none=True)
total_loss.backward()
self.optimizer.step()
toc = time.perf_counter()
dist.barrier()
barrier_toc = time.perf_counter()
if self.rank == 0:
print(
f"Epoch: {epoch}, Loss@rank-{self.rank}: {total_loss: .4f}, "
f"Elapsed: {toc - tic: .4f}, Slowest elapsed: {barrier_toc - tic: .4f}"
)
print(f"Rank-0 is telling the trainer that everything is done for the epoch {epoch}")
self.queue.send(True)
class Trainer:
def __init__(self, world_size: int, epochs: int = 20, rnn_type: str = "lstm") -> None:
self.world_size = world_size
self.epochs = epochs
self.rnn_type = rnn_type
self.queues: List[Connection] = []
self.ddp_free_port = str(find_free_port())
print(f"Trainer free port: {self.ddp_free_port}")
def run(self):
print("Start training")
processes = []
for rank in range(self.world_size):
print(f"Starting Process-{rank}")
if rank == 0:
recv, send = Pipe(duplex=True)
else:
recv, send = Pipe(duplex=False)
self.queues.append(send)
p = mp.Process(
target=init_process,
args=(rank, self.world_size, self.ddp_free_port, recv, self.rnn_type),
daemon=True,
)
p.start()
processes.append(p)
for epoch in range(self.epochs):
for rank in range(self.world_size):
self.queues[rank].send(epoch)
print("Training waiting for rank-0")
self.queues[0].recv()
for rank in range(self.world_size):
self.queues[rank].send(False)
self.queues[rank].close()
processes[rank].join()
processes[rank].close()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("-ws", "--world-size", type=int, default=2)
parser.add_argument("-e", "--epochs", type=int, default=10)
parser.add_argument("-rt", "--rnn-type", type=str, default="lstm")
args = parser.parse_args()
os.environ["LOGLEVEL"] = "DEBUG"
os.environ["OMP_NUM_THREADS"] = "1"
os.environ["MKL_NUM_THREADS"] = "1"
mp.set_start_method("spawn")
trainer = Trainer(world_size=args.world_size, epochs=args.epochs, rnn_type=args.rnn_type)
trainer.run()
print("Finished training")
The problem is that, the more processes i use to train the slower it becomes the training script.
So, for example:
python train.py -ws 2 gives me
Trainer free port: 61857
Start training
Starting Process-0
Starting Process-1
Training waiting for rank-0
Epoch: 0, Loss@rank-0: 5680.5479, Elapsed: 2.0102, Slowest elapsed: 2.0104
Rank-0 is telling the trainer that everything is done for the epoch 0
Training waiting for rank-0
Epoch: 1, Loss@rank-0: 5679.2422, Elapsed: 1.9503, Slowest elapsed: 1.9505
Rank-0 is telling the trainer that everything is done for the epoch 1
Training waiting for rank-0
Epoch: 2, Loss@rank-0: 5678.7778, Elapsed: 1.9748, Slowest elapsed: 1.9751
Rank-0 is telling the trainer that everything is done for the epoch 2
Training waiting for rank-0
Epoch: 3, Loss@rank-0: 5678.6035, Elapsed: 1.9699, Slowest elapsed: 1.9707
Rank-0 is telling the trainer that everything is done for the epoch 3
Training waiting for rank-0
Epoch: 4, Loss@rank-0: 5678.5361, Elapsed: 1.9849, Slowest elapsed: 1.9866
Rank-0 is telling the trainer that everything is done for the epoch 4
Training waiting for rank-0
Epoch: 5, Loss@rank-0: 5678.5078, Elapsed: 1.9881, Slowest elapsed: 1.9883
Rank-0 is telling the trainer that everything is done for the epoch 5
Training waiting for rank-0
Epoch: 6, Loss@rank-0: 5678.4937, Elapsed: 1.9276, Slowest elapsed: 1.9339
Rank-0 is telling the trainer that everything is done for the epoch 6
Training waiting for rank-0
Epoch: 7, Loss@rank-0: 5678.4844, Elapsed: 1.9945, Slowest elapsed: 1.9998
Rank-0 is telling the trainer that everything is done for the epoch 7
Training waiting for rank-0
Epoch: 8, Loss@rank-0: 5678.4766, Elapsed: 1.9860, Slowest elapsed: 1.9867
Rank-0 is telling the trainer that everything is done for the epoch 8
Training waiting for rank-0
Epoch: 9, Loss@rank-0: 5678.4688, Elapsed: 2.0003, Slowest elapsed: 2.0010
Rank-0 is telling the trainer that everything is done for the epoch 9
Rank-0 done!
Rank-1 done!
Finished training
while python train.py -ws 4 gives:
Trainer free port: 61956
Start training
Starting Process-0
Starting Process-1
Starting Process-2
Starting Process-3
Training waiting for rank-0
Epoch: 0, Loss@rank-0: 5680.6870, Elapsed: 2.5736, Slowest elapsed: 2.5743
Rank-0 is telling the trainer that everything is done for the epoch 0
Training waiting for rank-0
Epoch: 1, Loss@rank-0: 5679.3408, Elapsed: 2.5115, Slowest elapsed: 2.5118
Rank-0 is telling the trainer that everything is done for the epoch 1
Training waiting for rank-0
Epoch: 2, Loss@rank-0: 5678.8545, Elapsed: 2.4977, Slowest elapsed: 2.4980
Rank-0 is telling the trainer that everything is done for the epoch 2
Training waiting for rank-0
Epoch: 3, Loss@rank-0: 5678.6523, Elapsed: 2.5503, Slowest elapsed: 2.5506
Rank-0 is telling the trainer that everything is done for the epoch 3
Training waiting for rank-0
Epoch: 4, Loss@rank-0: 5678.5620, Elapsed: 2.5239, Slowest elapsed: 2.5242
Rank-0 is telling the trainer that everything is done for the epoch 4
Training waiting for rank-0
Epoch: 5, Loss@rank-0: 5678.5176, Elapsed: 2.5611, Slowest elapsed: 2.5615
Rank-0 is telling the trainer that everything is done for the epoch 5
Training waiting for rank-0
Epoch: 6, Loss@rank-0: 5678.4937, Elapsed: 2.6241, Slowest elapsed: 2.6243
Rank-0 is telling the trainer that everything is done for the epoch 6
Training waiting for rank-0
Epoch: 7, Loss@rank-0: 5678.4785, Elapsed: 2.5821, Slowest elapsed: 2.5824
Rank-0 is telling the trainer that everything is done for the epoch 7
Training waiting for rank-0
Epoch: 8, Loss@rank-0: 5678.4668, Elapsed: 2.6494, Slowest elapsed: 2.6499
Rank-0 is telling the trainer that everything is done for the epoch 8
Training waiting for rank-0
Epoch: 9, Loss@rank-0: 5678.4575, Elapsed: 2.6453, Slowest elapsed: 2.6455
Rank-0 is telling the trainer that everything is done for the epoch 9
Rank-0 done!
Rank-1 done!
Rank-2 done!
Rank-3 done!
Finished training
The same happens with the GRU.
From what i’ve seen from the windows Task Manager, there’s a lot of kernel time spent by the CPU:
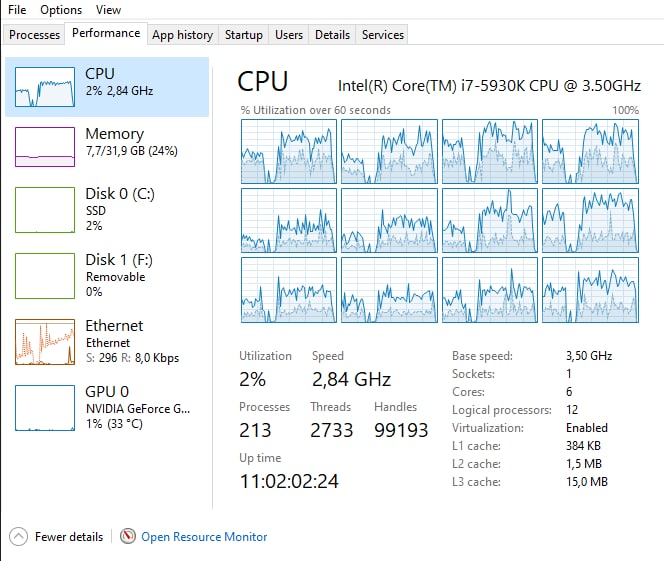
The other interesting thing is this: if i set the affinity of the processes being spawned with psutil, like this:
process_handle = psutil.Process(p.pid)
process_handle.cpu_affinity([rank + 8])
so that they only have visible the last four cores, core-0 and core-2 are used only for kernel stuff:
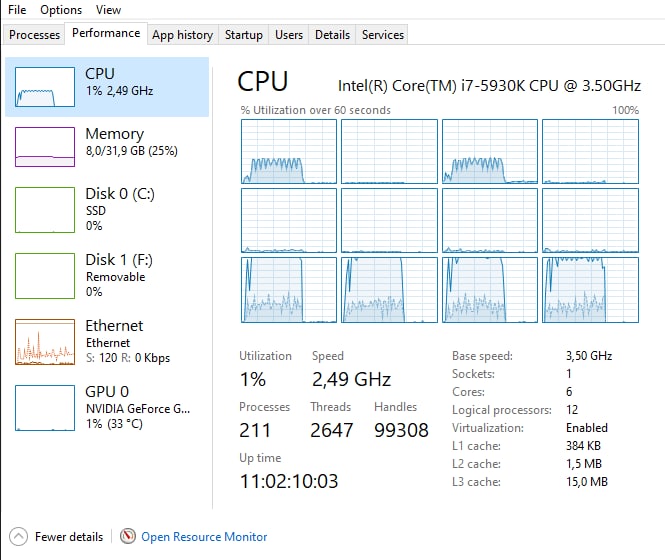
and if i increase the number of training processes, those two cores are used even more. So, with 6 agents i have something like this:
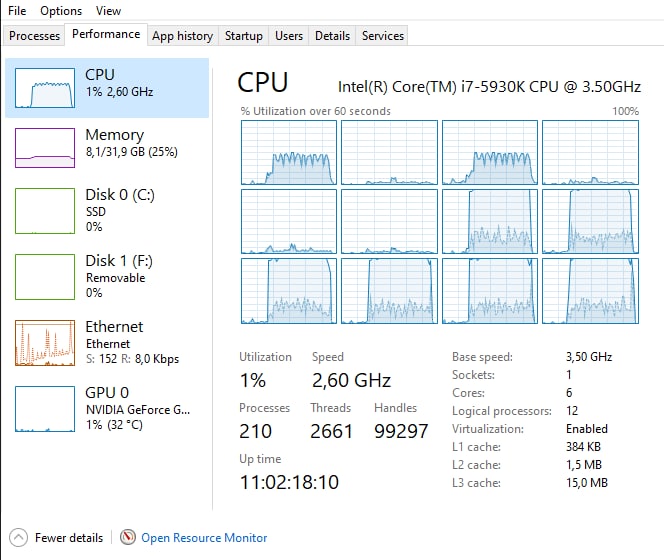
The collected environement info are:
Collecting environment information...
PyTorch version: 1.13.0+cpu
Is debug build: False
CUDA used to build PyTorch: Could not collect
ROCM used to build PyTorch: N/A
OS: Microsoft Windows 10 Pro
GCC version: Could not collect
Clang version: Could not collect
CMake version: Could not collect
Libc version: N/A
Python version: 3.8.10 (tags/v3.8.10:3d8993a, May 3 2021, 11:48:03) [MSC v.1928 64 bit (AMD64)] (64-bit runtime)
Python platform: Windows-10-10.0.19045-SP0
Is CUDA available: False
CUDA runtime version: Could not collect
CUDA_MODULE_LOADING set to: N/A
GPU models and configuration: GPU 0: NVIDIA GeForce GTX TITAN X
Nvidia driver version: 516.94
cuDNN version: Could not collect
HIP runtime version: N/A
MIOpen runtime version: N/A
Is XNNPACK available: True
Versions of relevant libraries:
[pip3] mypy==0.931
[pip3] mypy-extensions==0.4.3
[pip3] numpy==1.23.4
[pip3] pytorch-lightning==1.8.2
[pip3] torch==1.13.0
[pip3] torch-tb-profiler==0.4.0
[pip3] torchmetrics==0.10.3
[pip3] torchvision==0.14.0
[conda] Could not collect
Why is this happening? Is there a way to prevent this kind of behaviour?
Thank you
Federico