Hi I’m a newbie in LSTM and I want to ask basic question.
I’m training below network and xi is 64 bit data.
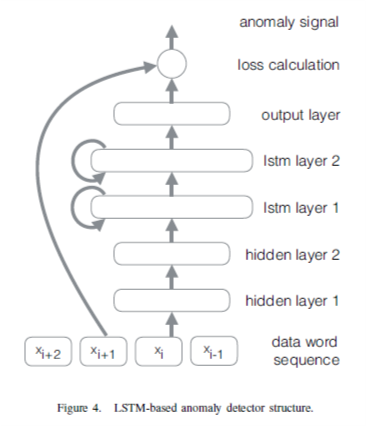
This paper said
“These bits(64bit data) are transformed by two non-recurrent hidden layers, each with 128 units and tanh activation functions.
The output of the linear layers is fed into two recurrent LSTM layers, each with 512 units and tanh activation functions.”
and this is snippet code of me
self.lstm = nn.LSTM(input_size=input_size, hidden_size=hidden_size,
num_layers=num_layers, batch_first=True)
self.fc = nn.Linear(hidden_size, num_classes)
def forward(self, x):
h_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size)) #([1, 50656, 64])
c_0 = Variable(torch.zeros(
self.num_layers, x.size(0), self.hidden_size)) #([1, 50656, 64])
# Propagate input through LSTM
ula, (h_out, _) = self.lstm(x, (h_0, c_0))
My question is how should I have to set ‘hidden_size’ and ‘num_layers’ in this network??
How can I set fully connected layer in this case??
Actually, I can find Time-Series anomaly detection LSTM in single variable code in Google.
But, hard to find Time-Series anomaly detection LSTM in multivariate variable like my case.
This is not my homework and,
Any comment or existing tutorial will be appreciate.