Hi,
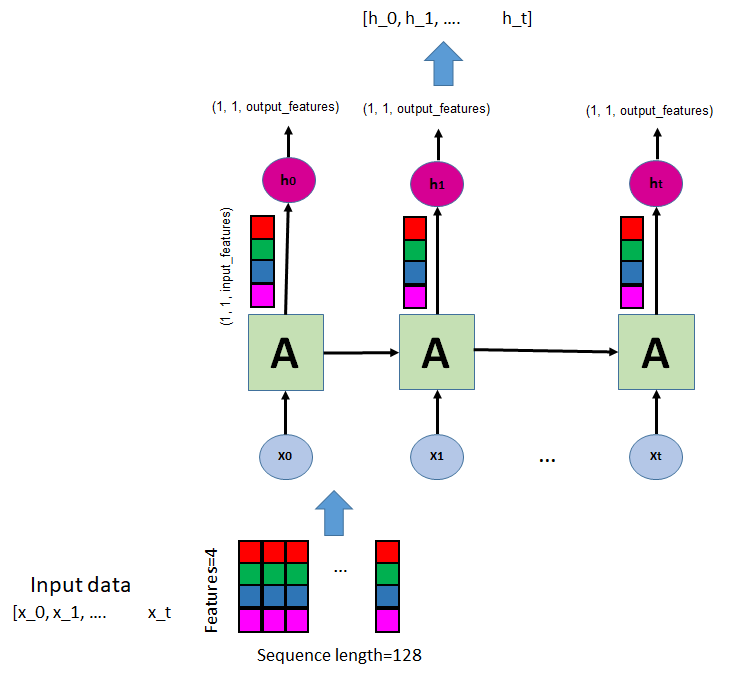
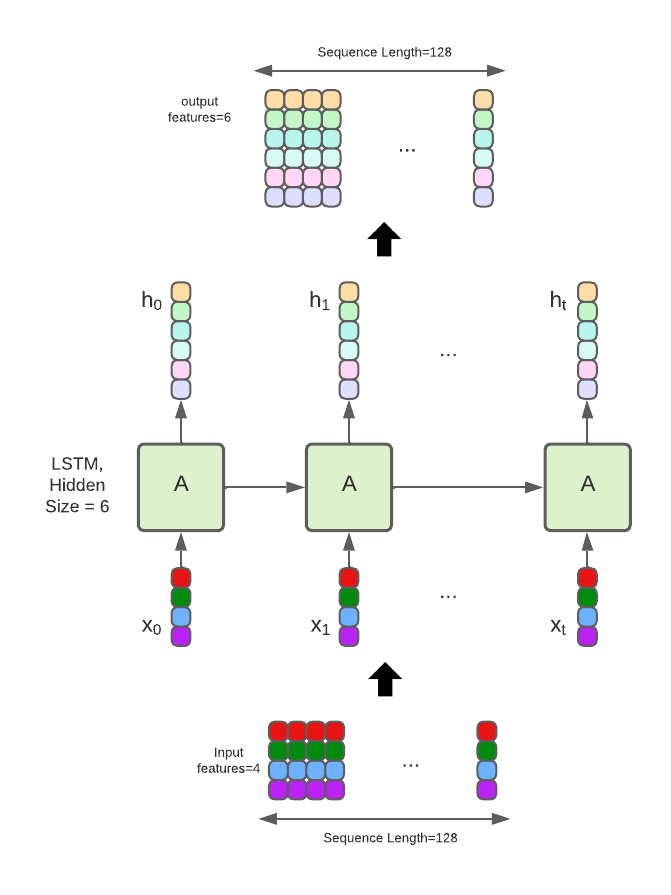
I have a sequence of [Bacth=2, SeqLenght=128, InputFeatures=4]
I was reading about LSTM, but I am confuse.
According the documentation , there are two main parameters :
- input_size – The number of expected features in the input x
- hidden_size – The number of features in the hidden state h
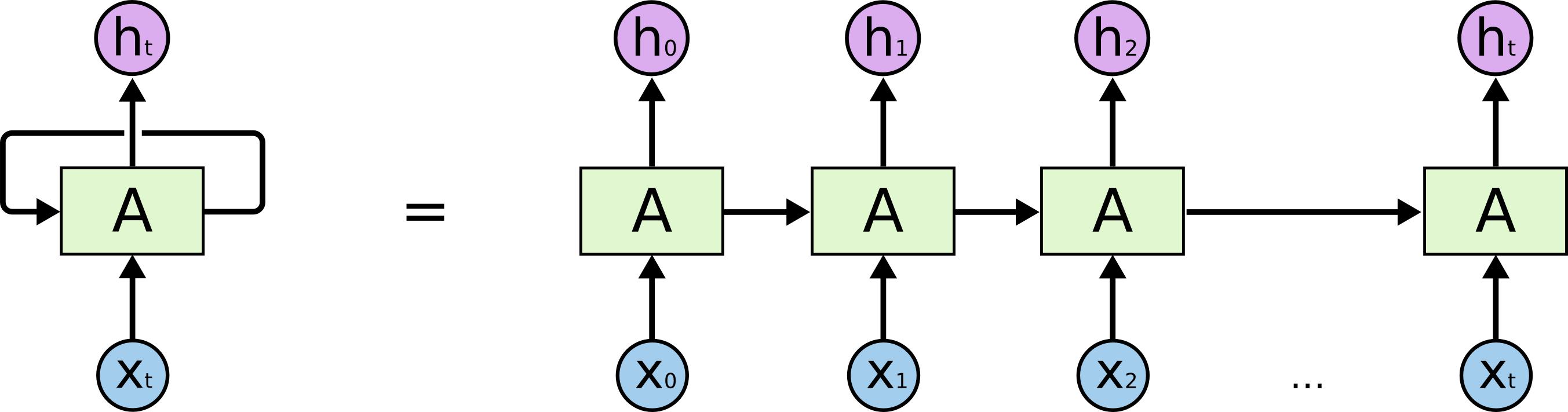
Given and input, the LSTM outputs a vector h_n containing the final hidden state for each element in the sequence, however this size is [1, Batch, hidden_size], then I expect something like [SeqLength, Batch, hidden_size],
Also I noticed that LSTM does not matter the SeqLenght, so someone can me explain me how LSTM resolve the variable length?
LSTM can be thought as a data fusion, because the input features are reduced to hidden_size vector?
I am sorry, perhaps I am misunderstanding, but I like to know in detail how LSTM is working in order to use it properly.