I think i’m figure out why this exception happens, but I’ve no idea how to solve it.
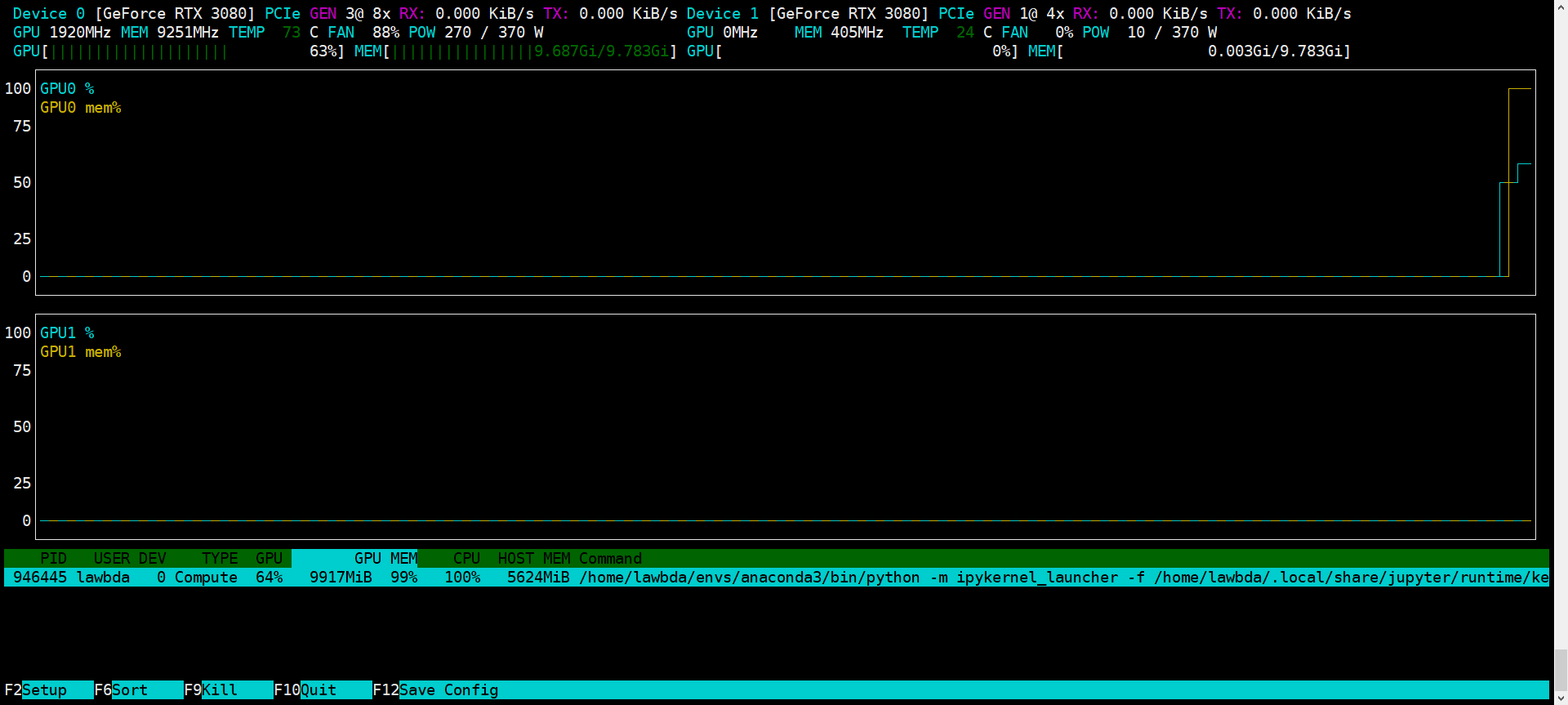
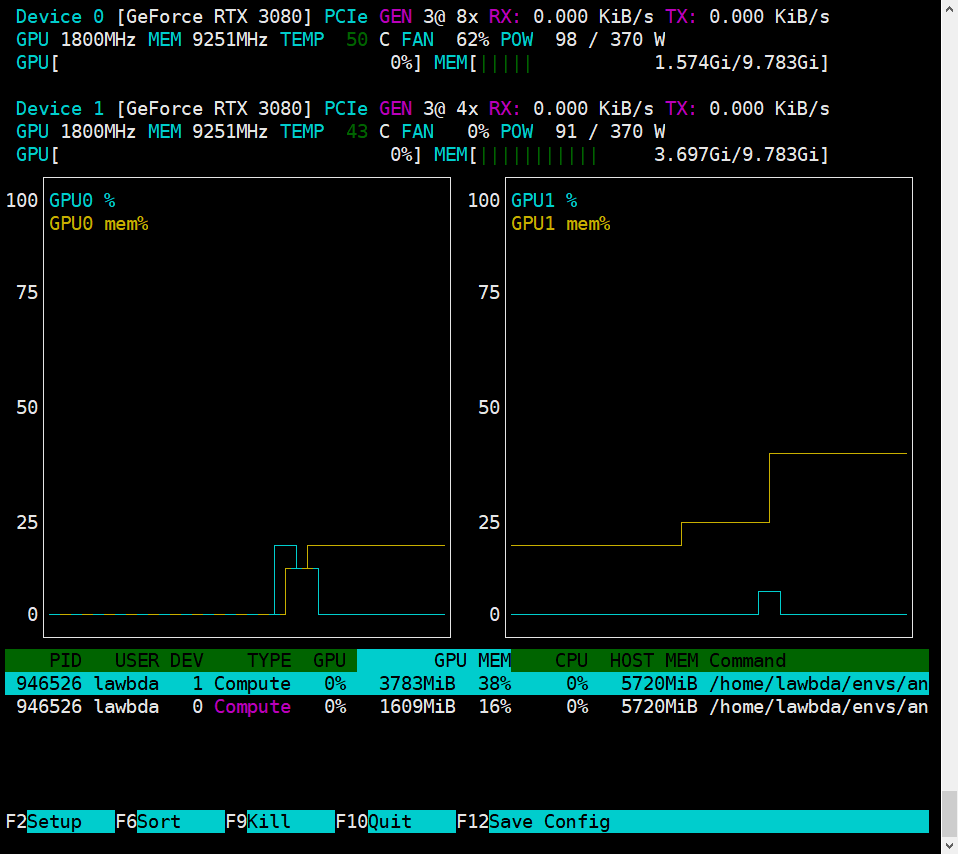
My machine have two RTX-3080, which means I can run torch program both on cuda:0 and cuda:1.
However, when cuda:0 have been allocated maxium memory(10GB), I try to run the same program on cuda:1 there be an exception.
Though cuda:1 has been assign to my model, when call LSTM forward() framwork still try to allocate new memory on cuda:0 which may be the default device of cuda().
Here’s the code and some details.
My torch version here:
'1.9.0+cu111'
class LSTMEncoder(BaseEncoder):
def __init__(self,input_shape:int,
output_shape:int,
padding_size:int,
num_layers:int=2,
bi_direction:bool=False,
active_func:str='relu',
dropout_ratio:float=0.5,
device:str='cpu',
out_type='last'):
super(LSTMEncoder,self).__init__(input_shape=input_shape,
output_shape=output_shape,
active_func=active_func,
dropout_ratio=dropout_ratio,
device=device)
self.input_shape = input_shape
self.output_shape = output_shape
self.num_layers = num_layers
self.bi_direction = bi_direction
self.out_type = out_type
self.BatchNorm = torch.nn.BatchNorm1d(num_features=padding_size).to(self.device_type)
self.LSTMLayer = torch.nn.LSTM(input_size=input_shape,
hidden_size=output_shape,
num_layers=num_layers,
dropout=dropout_ratio,
bidirectional=bi_direction,
batch_first=True,
device=self.device_type)
self.LSTMLayer.to(self.device_type)
def forward(self,in_tensor):
batch_size = in_tensor.shape[0]
in_tensor = in_tensor.to(self.device_type).float()
print(in_tensor.device)
lstm_tensor,(hn,cn) = self.LSTMLayer(in_tensor)
lstm_tensor = self.ActiveFunc(in_tensor)
out_tensor = hn.view(self.num_layers, 2 if self.bi_direction == True else 1,
batch_size, self.output_shape)
if self.out_type == 'last':
out_tensor = out_tensor[-1].permute(1,0,2).mean(dim=1)
else:
out_tensor = lstm_tensor
return out_tensor
And the exceptions when I try to call the encoder.
---------------------------------------------------------------------------
RuntimeError Traceback (most recent call last)
<ipython-input-46-c3f0832944ba> in <module>
----> 1 q_feature = get_query_representation(query)
<ipython-input-38-38047efcba4d> in get_query_representation(batch_query)
54
55 query_emb_tensor = get_query_embedding(batch_query)
---> 56 query_enc_tensor = QueryEncoder(query_emb_tensor)
57
58 return query_enc_tensor
~/envs/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
<ipython-input-31-f48883ffc9e0> in forward(self, in_tensor)
56 in_tensor = in_tensor.to(self.device_type).float()
57 print(in_tensor.device)
---> 58 lstm_tensor,(hn,cn) = self.LSTMLayer(in_tensor)
59
60 lstm_tensor = self.ActiveFunc(in_tensor)
~/envs/anaconda3/lib/python3.8/site-packages/torch/nn/modules/module.py in _call_impl(self, *input, **kwargs)
1049 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1050 or _global_forward_hooks or _global_forward_pre_hooks):
-> 1051 return forward_call(*input, **kwargs)
1052 # Do not call functions when jit is used
1053 full_backward_hooks, non_full_backward_hooks = [], []
~/envs/anaconda3/lib/python3.8/site-packages/torch/nn/modules/rnn.py in forward(self, input, hx)
677 self.check_forward_args(input, hx, batch_sizes)
678 if batch_sizes is None:
--> 679 result = _VF.lstm(input, hx, self._flat_weights, self.bias, self.num_layers,
680 self.dropout, self.training, self.bidirectional, self.batch_first)
681 else:
RuntimeError: cuDNN error: CUDNN_STATUS_INTERNAL_ERROR
It seems that my program hits the OOM exception. But I already have assign cuda:1 to it.
I want to know why LSTMLayer acts so weird when called forward()