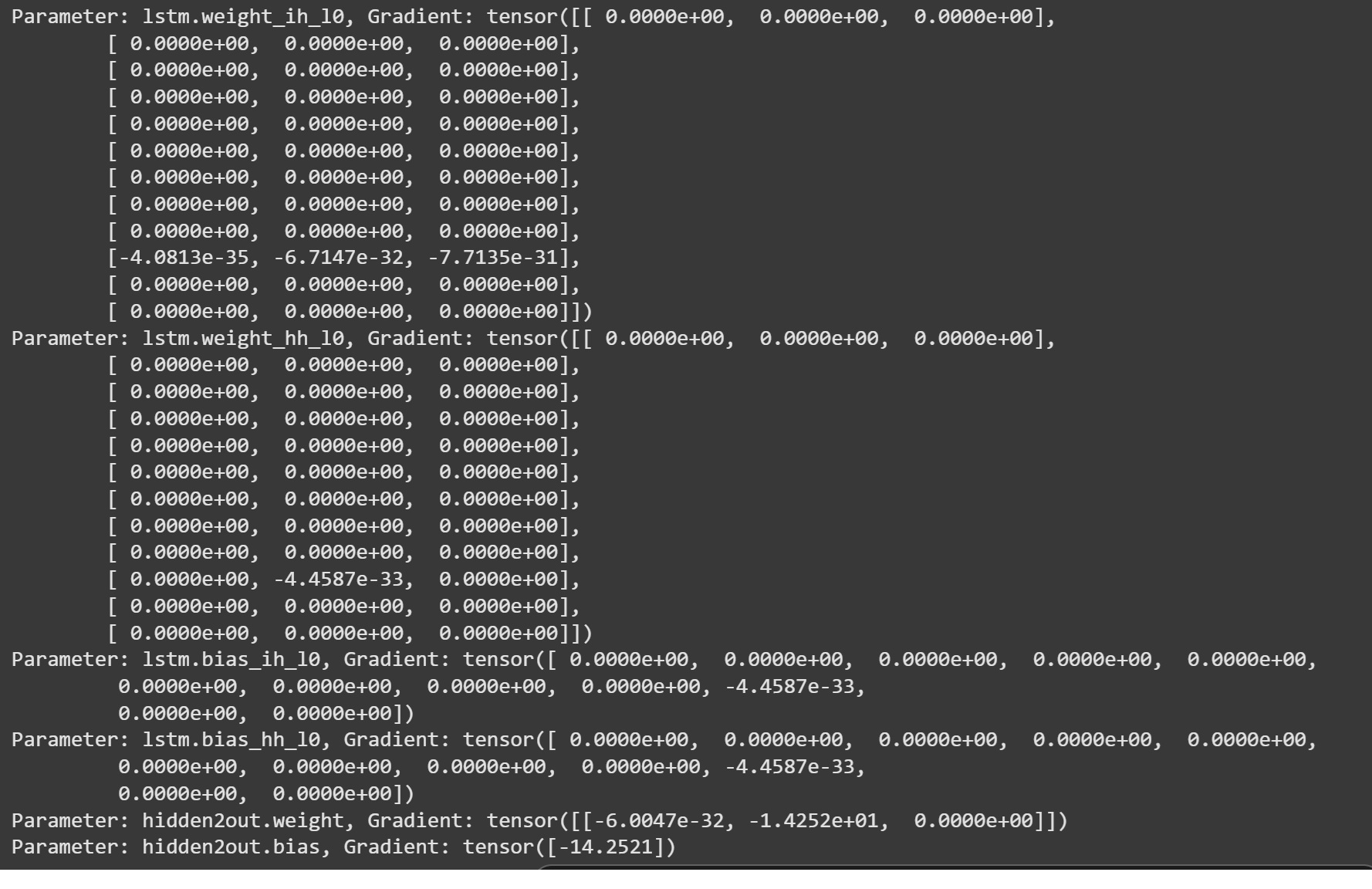
Hello all, hoping someone can point out a flaw in my model. I have an LSTM model that computes the loss only at the end of a sequence (sequence of length 5 using batching). I apply a linear layer to the final hidden state to compute an output and use MSE as the loss function. When I run the model, my linear layer weights will update, but the LSTM weights will not. When I check the gradients of the LSTM weights, they are all zero, or effectively zero. Any help is greatly appreciated. code below:
batch_proportion = .1
batch_size = int(np.round(batch_proportion * x_train.shape[0]))
dataset = TensorDataset(x_train_tensors,y_train_tensors)
data_loader = DataLoader(dataset,batch_size=batch_size,shuffle=True)
#determine LSTM structure
input_dim = inputs.shape[1]
hidden_dim = 3
target_dim = 1
class LSTM_Vol(nn.Module):
def __init__(self, input_dim, hidden_dim, target_dim):
super().__init__()
self.lstm = nn.LSTM(input_dim, hidden_dim, batch_first=True) #sets up the LSTM object; data tensor is set up with samples being the first dimension
self.hidden2out = nn.Linear(hidden_dim, target_dim) #sets up a linear layer object to map hidden state to a prediction
def forward(self, batch, batch_size): #takes in vol data points and passes it through the RNN...if vol_matrix is unbatched, vol_matrix has dim seq_len x input_dim; for batched, seq_len x batch_size x input_dim
output, (hn, cn) = self.lstm(batch,(torch.full((1,batch_size,hidden_dim),15,dtype=torch.float32),torch.full((1,batch_size,hidden_dim),15,dtype=torch.float32))) #hn will be the final hidden state(s) (will be of dimension 1 x hidden_dim for unbatched; 1 x batch_size x hidden_dim for batched)
predict = self.hidden2out(hn.view(-1,hidden_dim)) #applies a linear transform on the final hidden state to return a vol prediction
return predict #I want to return the final output of the RNN...will compute loss on this output
model = LSTM_Vol(input_dim, hidden_dim, target_dim)
#define loss function and optimizer method
loss_function = nn.MSELoss()
optimizer = optim.SGD(model.parameters(), lr=0.5)
num_epochs = 1
epoch = np.arange(num_epochs)
epoch_avg_loss = np.zeros((epoch.size))
model.train() #put model in training mode
for t in epoch:
counter = 0
cum_loss = 0
for batch_X, batch_y in data_loader:
optimizer.zero_grad()
vol_predict = model.forward(batch_X,batch_X.shape[0]) #output with dimension 1 x batch_size x 1
loss = loss_function(vol_predict.view(-1,1),batch_y) #batch_y has dimension batch_size x 1
loss.backward()
optimizer.step()
cum_loss += loss
counter += 1
epoch_avg_loss[t] = math.sqrt(cum_loss / counter)
for name, param in model.named_parameters():
if param.requires_grad: # Only parameters that require gradients will have a .grad attribute
print(f"Parameter: {name}, Gradient: {param.grad}")