Hi guys, I am new to deep learning models and pytorch. I have been working on a multiclass text classification with three output categories. I used LSTM model for 30 epochs, and batch size is 32, but the accuracy for the training data is fluctuating and the accuracy for validation data does not change. Here are my codes.
class AdvancedModel(nn.Module):
def __init__(self, vocab_size, embedding_dim, hidden_dim, output_dim, n_layers,
bidirectional, dropout, pad_idx):
super().__init__()
self.embedding = nn.Embedding(vocab_size, embedding_dim, padding_idx = pad_idx)
# Define some parameters
self.output_dim = output_dim
self.n_layers = n_layers
self.hidden_dim = hidden_dim
# Define layers
self.lstm = nn.LSTM(embedding_dim, hidden_dim, n_layers, bidirectional=bidirectional, batch_first=True)
self.dropout = nn.Dropout(dropout)
self.fc = nn.Linear(hidden_dim, output_dim)
def forward(self, text, text_lengths):
#text = [sent len, batch size]
embedded = self.dropout(self.embedding(text))
#embedded = [sent len, batch size, emb dim]
#pack sequence. Clambing the lengths to avoid errors in some bugs
packed_embedded = nn.utils.rnn.pack_padded_sequence(embedded, text_lengths.clamp(min=1, max=50))
# Initializing hidden state for first input using method defined below
hidden = self.init_hidden(BATCH_SIZE)
lstm_out, hidden = self.lstm(packed_embedded, hidden)
unpacked, unpacked_len = torch.nn.utils.rnn.pad_packed_sequence(lstm_out, batch_first=True)
lstm_out=unpacked[:, -1, :]
out = self.dropout(lstm_out)
out = self.fc(out)
return out
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device))
return hidden
Here is the parameters I use:
INPUT_DIM = len(TEXT.vocab)
EMBEDDING_DIM = 100
HIDDEN_DIM = 300
OUTPUT_DIM = len(LABEL.vocab)
N_LAYERS = 1
BIDIRECTIONAL = False
DROPOUT = 0.5
The rest of the codes are based on this:
https://github.com/bentrevett/pytorch-sentiment-analysis/blob/master/5%20-%20Multi-class%20Sentiment%20Analysis.ipynb
Here is the training accuracy I get:
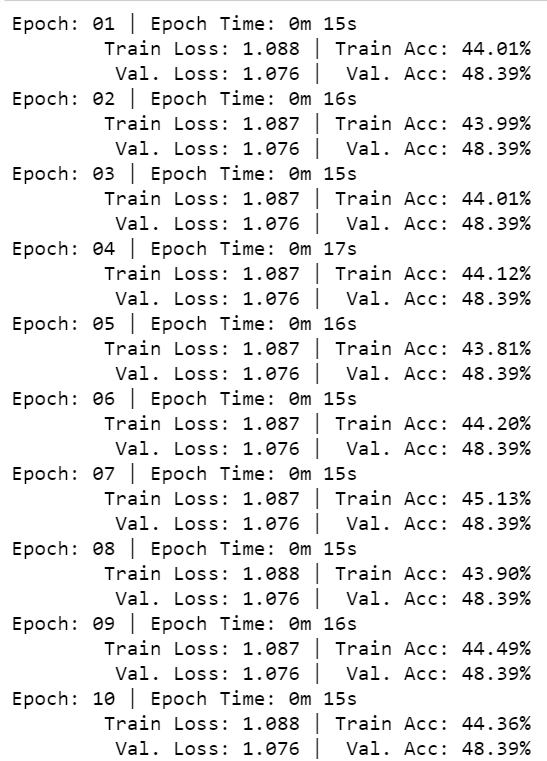
The validation accuracy never changes for the whole 30 epochs.
It would be really helpful if anyone knows what is wrong here. Thank you!