Hello everyone,
I’m trying to build an LSTM model to predict if a customer will qualify for a loan given multiple data points data that are accumulated over a 5-day window (customer is discarded on day 6). My target variable is binary. Below is a snapshot of the data set for reference.
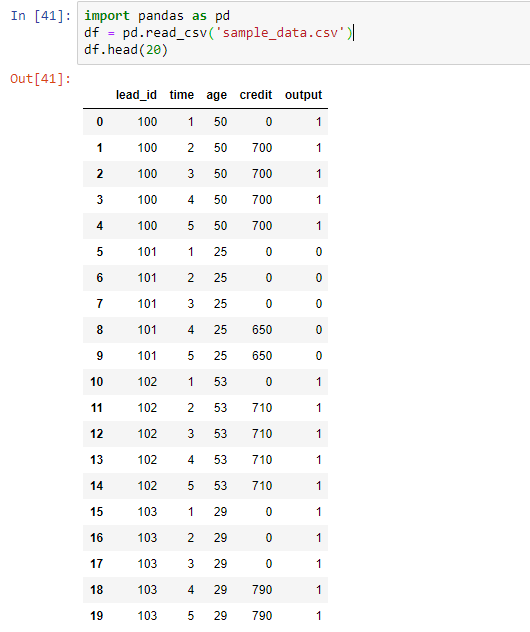
As you can see, “age” is available upon lead submission while credit score might get pulled anytime between day 2 and day 5. My ultimate goal is to have a model that can predict the outcome of a lead based on the data available at any point in time. For example, a lead with “age” = 25 and no credit score pulled on day 4 will have a low likelihood to convert (even lower, close to 0, if there’s still no credit score on day 5) but if the same lead had the credit score pulled on day 2 - assuming the credit score is good - it will indicate high intent by the consumer which would result in high likelihood to close. Basically, I’m looking to build a lead scoring model that updates its scores after each day passes and as new data is collected.
The Pytorch issue that I ran into is that I can’t understand how to reshape the input data in a way that makes sense for what I’m trying to do. I read this thread but it didn’t help: Understanding LSTM input
I understand that I have to reshape the data to be of shape (batch, time-steps, input_size). I tried using this method:
df = pd.read_csv("sample_data.csv")
a = torch.Tensor(df.values)
a.unsqueeze_(-1)
a = a.expand(100,5,5)
However the result is that each data point is repeated 5 times along the X axis as you can see below.
tensor([[[100., 100., 100., 100., 100.],
[ 1., 1., 1., 1., 1.],
[ 50., 50., 50., 50., 50.],
[ 0., 0., 0., 0., 0.],
[ 1., 1., 1., 1., 1.]],
[[100., 100., 100., 100., 100.],
[ 2., 2., 2., 2., 2.],
[ 50., 50., 50., 50., 50.],
[700., 700., 700., 700., 700.],
[ 1., 1., 1., 1., 1.]],
But my understanding is that each block should contain the 5 time-steps for each lead:
tensor([[[100., 100., 100., 100., 100.],
[ 1., 2., 3., 4., 5.],
[ 50., 50., 50., 50., 50.],
[ 0., 700., 700., 700., 700.],
[ 1., 1., 1., 1., 1.]],
Any help and possibly some starter code would be highly appreciated