Hey,
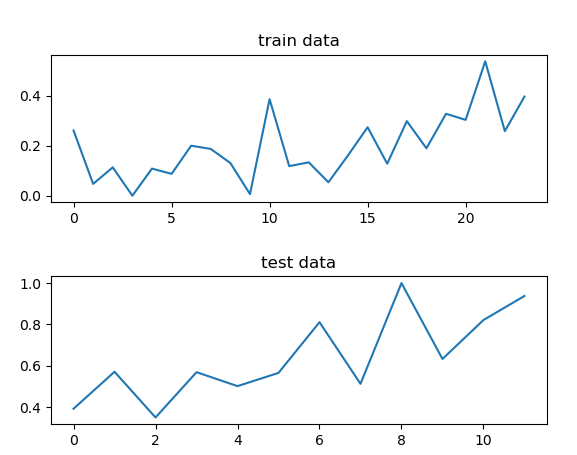
I want to predict some prices using a dataset with 36 records. I use 24 of the for training and 12 for testing. The model perfectly predicts the train data (so the architecture should work correctly?), but is bad on the test data. Is this due to overfitting/less data or do I have a error in my code/logic:
class LSTMPrediction(nn.Module):
def __init__(self, input_dim, hidden_dim, batch_size, output_dim=1,num_layers=1):
super(LSTMPrediction, self).__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.batch_size = batch_size
self.num_layers = num_layers
self.lstm1 = nn.LSTM(self.input_dim, self.hidden_dim)
self.linear = nn.Linear(self.hidden_dim, output_dim)
def init_hidden(self):
h0 = torch.zeros(self.num_layers, self.batch_size, self.hidden_dim, dtype=torch.float)
c0 = torch.zeros(self.num_layers, self.batch_size, self.hidden_dim, dtype=torch.float)
return (h0, c0)
def forward(self, x):
out, (h0, c0) = self.lstm1(x, self.init_hidden())
output = self.linear(out)
return output
HIDDEN_SIZE = 51
BATCH_SIZE = 1
EPOCHS = 1000
INPUT_DIM = 1
data = np.array(pd.read_csv("data.csv", usecols=[1]).dropna())
data = data.reshape(36,1)
scaler = MinMaxScaler()
data= scaler.fit_transform(data)
data = data.reshape(-1)
xtrain, xtest = data[:24], data[-12:]
model = LSTMPrediction(INPUT_DIM, HIDDEN_SIZE, BATCH_SIZE)
model.float()
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr = 0.01)
ytrain = torch.from_numpy(xtrain[1:]).float()
ytest = torch.from_numpy(xtest[1:]).float()
xtrain = torch.from_numpy(xtrain[:-1]).view(-1, BATCH_SIZE, 1).float()
xtest = torch.from_numpy(xtest[:-1]).view(-1, BATCH_SIZE, 1).float()
for i in range(1, EPOCHS):
prediction = model.forward(xtrain).view(-1)
optimizer.zero_grad()
loss = criterion(prediction, ytrain)
print("Iteration {}, loss: {}".format(i, loss))
loss.backward()
optimizer.step()
with torch.no_grad():
prediction = model.forward(xtest).view(-1)
loss = criterion(prediction, ytest)
plt.title("MESLoss: {:.5f}".format(loss))
plt.plot(prediction.detach().numpy(), label="pred")
plt.plot(ytest.detach().numpy(), label="true")
plt.legend()
plt.show()
Predicting the train data results in a MSELoss of nearly zero.
Prediction the test data results in a MSELoss of 0.8
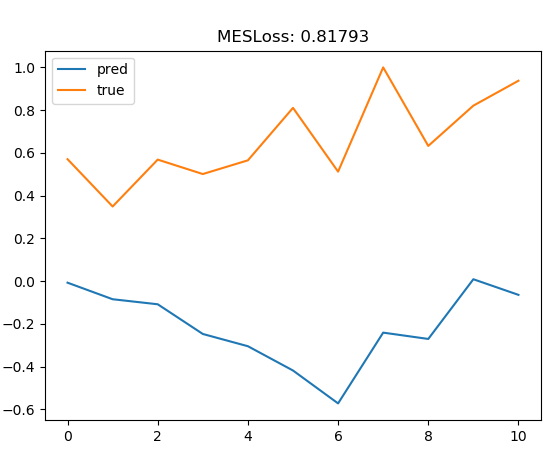
Is there any error in my Code?
Thanks for helping