I am trying to replicate the paper [[1504.00941] A Simple Way to Initialize Recurrent Networks of Rectified Linear Units](A Simple Way to Initialize Recurrent Networks of Rectified Linear Units), the addition problem especially with T = 150, but I am finding that LSTMs seem to jump from baseline to perfection with almost no noise 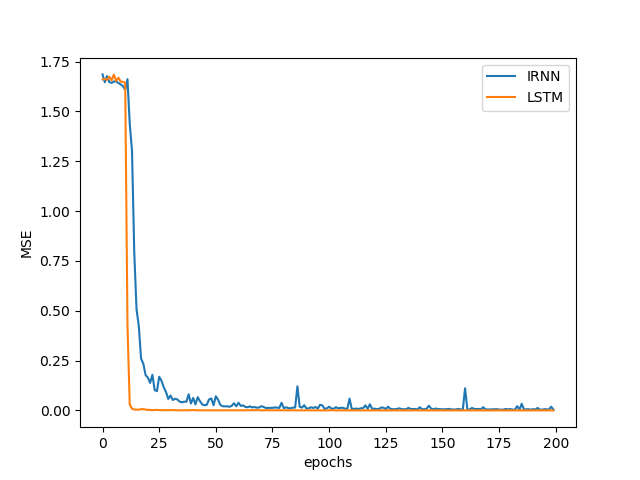 . I think there might be a problem with how I implemented LSTM unit, but I cannot seem to find any problem.
. I think there might be a problem with how I implemented LSTM unit, but I cannot seem to find any problem.
For both architectures I am using 25 hidden units and for LSTM I am using a learning rate of 0.1 and for the IRNN 0.005. The remaining are set by the default by the argparser in the main.
class LSTM(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(LSTM, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.LSTM(input_size, hidden_size, batch_first=True)
self.output_weights = nn.Linear(hidden_size, output_size)
self.init_bias()
def forward(self, inp):
_, hnn = self.rnn(inp)
out = self.output_weights(hnn[0][0])
return out
def init_bias(self, value=1):
# initialize the recurrent bias to value
# if look the documentation you can find two paramenters
# for the bias in the recurrent layer
for names in self.rnn._all_weights:
for name in filter(lambda n: "bias" in n, names):
bias = getattr(self.rnn, name)
n = bias.size(0)
start, end = n // 4, n // 2
bias.data[start:end].fill_(value / 2)
# Model taken from arXiv:1504.00941v2
class IRNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size):
super(IRNN, self).__init__()
self.hidden_size = hidden_size
self.rnn = nn.RNN(input_size, hidden_size,
nonlinearity='relu', batch_first=True, bias=True)
self.output_weights = nn.Linear(hidden_size, output_size)
# Parameters initialization
self.rnn.state_dict()['weight_hh_l0'].copy_(th.eye(hidden_size))
self.rnn.bias_ih_l0.data.fill_(0)
self.rnn.bias_hh_l0.data.fill_(0)
self.rnn.state_dict()['weight_ih_l0'].copy_(
th.randn(hidden_size, input_size) / hidden_size)
def forward(self, inp):
_, hnn = self.rnn(inp)
out = self.output_weights(hnn[0])
return out
Maybe pytorch does something that i don’t know in the nn.LSTM class.
I think the rest is fairly straightforword and it is the same for both architectures
my main is
import matplotlib.pyplot as plt
import torch as th
import torch.nn as nn
from benchmark_problems import Addition_Dataset
from models import *
from train import train
import argparse
import numpy as np
parser = argparse.ArgumentParser(
description='PyTorch Addition problem with LSTM')
parser.add_argument('--n_hidden', type=int, default=100,
help='number of hidden units')
parser.add_argument('--clip', type=int, default=10,
help='gradient clipping')
parser.add_argument('--lr', type=float, default=.01,
help='learning rate')
parser.add_argument('--n_epochs', type=int, default=200,
help='number of epochs')
parser.add_argument('--cuda', action='store_true',
help='use CUDA')
parser.add_argument('--N_test', type=int, default=1000,
help='number of test datapoints')
parser.add_argument('--N_train', type=int, default=100000,
help='number of training datapoints')
parser.add_argument('--T', type=int, default=150,
help='sequence length')
parser.add_argument('--seed', type=int, default=100,
help='random seed')
parser.add_argument('--batch_test', type=int, default=1000,
help='mini batch length for test set')
parser.add_argument('--batch_train', type=int, default=16,
help='mini batch length for train set')
parser.add_argument('--verbose', action='store_true',
help='print loss every epoch')
parser.add_argument('--model', type=str, default='LSTM',
help='choose between LSTM, np_RNN')
parser.add_argument('--path', type=str, default='model_state/state_epoch',
help='path where to save model')
parser.add_argument('--load_path', type=str, default='',
help='path where to load the model')
parser.add_argument('--save_fig', type=str, default='',
help='path where to save the figure')
args = parser.parse_args()
th.manual_seed(args.seed)
np.random.seed(args.seed)
if th.cuda.is_available():
if not args.cuda:
print("WARNING: You have a CUDA device, so you should probably run with --cuda")
else:
th.cuda.manual_seed(args.seed)
th.backends.cudnn.benchmark = True
# Prepare the data
dtype = th.FloatTensor
add_problem = Addition_Dataset(args.T, dtype)
train_loader = add_problem.get_loader(args.N_train, args.batch_train)
test_loader = add_problem.get_loader(args.N_test, args.batch_test)
# Initialize the model
# LSTM taken from models.py
if args.model == 'LSTM':
model = LSTM(2, args.n_hidden, 1)
elif args.model == 'np_RNN':
model = np_RNN(2, args.n_hidden, 1)
elif args.model == 'IRNN':
model = IRNN(2, args.n_hidden, 1)
if args.cuda:
model.cuda()
if args.load_path:
model.load_state_dict(th.load(args.load_path))
criterion = nn.MSELoss()
optimizer = th.optim.SGD(model.parameters(), lr=args.lr)
model, losses = train(model, criterion, optimizer, train_loader, test_loader,
clip=args.clip, n_epochs=args.n_epochs, use_cuda=args.cuda, verbose=args.verbose, PATH=args.path)
np.save(args.save_fig + 'losses.npy', losses)
plt.plot(losses)
plt.ylim([0, 1])
plt.ylabel('MSE')
plt.xlabel('Epoch')
plt.savefig(args.save_fig + 'losses.png')
and my training procedure is
train.py
import torch as th
import tqdm
from torch.autograd import Variable as V
import numpy as np
def train(model, criterion, optimizer, train_loader, test_loader, clip=10, n_epochs=1, use_cuda=False, verbose=True, mnist=False, PATH='model_state/state_epoch'):
losses = np.zeros(n_epochs)
i = 0
if mnist:
correct = np.zeros(n_epochs)
for epoch in tqdm.tqdm(range(n_epochs)):
for x_batch, y_batch in train_loader:
if use_cuda:
x_batch = V(x_batch).cuda()
y_batch = V(y_batch).cuda()
else:
x_batch = V(x_batch)
y_batch = V(y_batch)
optimizer.zero_grad()
output = model.forward(x_batch)
loss = criterion(output, y_batch)
loss.backward()
th.nn.utils.clip_grad_norm(model.parameters(), clip)
optimizer.step()
loss_test = 0
for x_batch, y_batch in test_loader:
if use_cuda:
x_batch = V(x_batch).cuda()
y_batch = V(y_batch).cuda()
else:
x_batch = V(x_batch)
y_batch = V(y_batch)
output = model.forward(x_batch)
loss_test += criterion(output, y_batch)
if mnist:
correct[i] += (th.max(output.data, 1)[1] == y_batch.data).sum()
losses[i] = loss_test / len(test_loader)
if verbose:
print('Loss at epoch', epoch + 1, ':', losses[i])
if mnist:
print('Accuracy at epoch', epoch + 1, ':', correct[i])
i += 1
th.save(model.state_dict(), PATH + str(i) + '.pt')
if not mnist:
return model, losses
else:
return model, losses, correct / len(test_loader) / test_loader.batch_size