This is the link to my code. experiment.py is the main file
What I do is:
I generate artificial time-series data (sine waves)
I cut those time-series data into small sequences
The input to my model is a sequence of time 0...T, and the output is a sequence of time 1...T+1
What happens is:
The training and the validation losses goes down smoothly
The test loss is very low
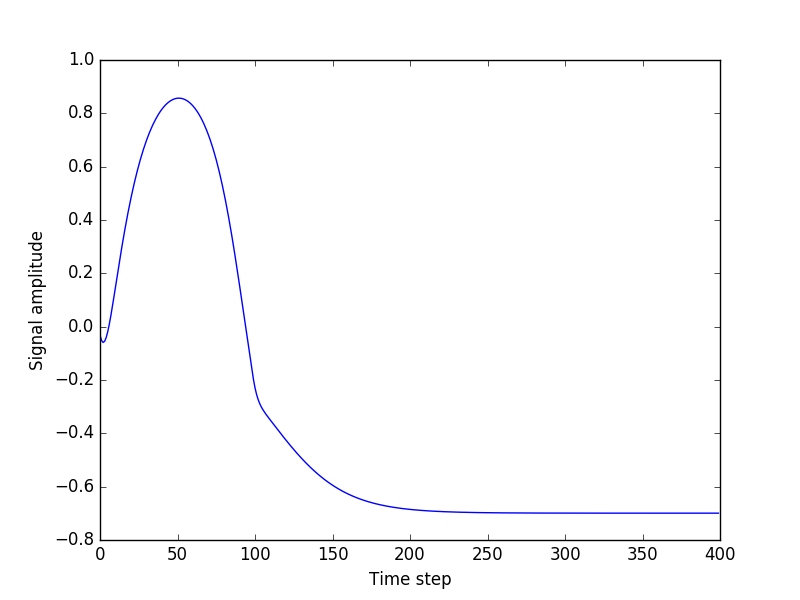
However, when I try to generate arbitrary-length sequences, starting from a seed (a random sequence from the test data), everything goes wrong. The output always flats out
I simply don’t see what the problem is. I am playing with this for a week now, with no progress in sight.
I would be very grateful for any help.
Thank you
The model and training code looks good. I think there’s something weird in your get_batch function or related batching logic - by turning down batch_size it unexpectedly runs slower but gets better results:
Epoch 11 -- train loss = 0.005119644441312117 -- val loss = 0.01055418627721996
I rechecked the get_batch function. You were right, there was were two problems with it (the chosen batch_size didn’t propagate to this function + the targets range wasn’t chosen correctly). I modified the github repository.
However, this still doesn’t resolve the problem. I tried with different batch sizes, but it still flats out
It might be that the long range dependency is too long for such a small model. It can learn to “fit the data” when the teacher is holding its hand, but is never trained on its own outputs, so that’s as far as it goes.
Thank you so much @spro !
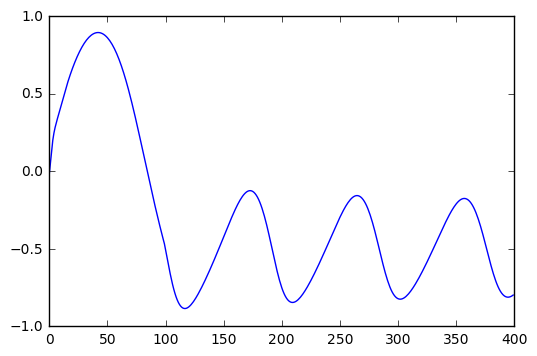
I was able to regenerate your output.
I tried with 2 sine-waves components as well (while reducing the steps as you mentioned), and it works beautifully
It is unstable for 3 sine-wave components, but I think this is due to the issue you mentioned, that I don’t train the model on its outputs.
I will train the model on its outputs and see how it performs
@spro: Would you recommend me any paper/blog/tutorial on how to train the model on its outputs?
I understand the general idea, but I am having doubts about its details
Thank you for the LSTM threads, I’m learning so much from them!
(This one and the more recent one, but I felt that this was better fitting here.)
A few observations that may or may not be interesting regarding the pytorch example (in particular with (entire) batch:
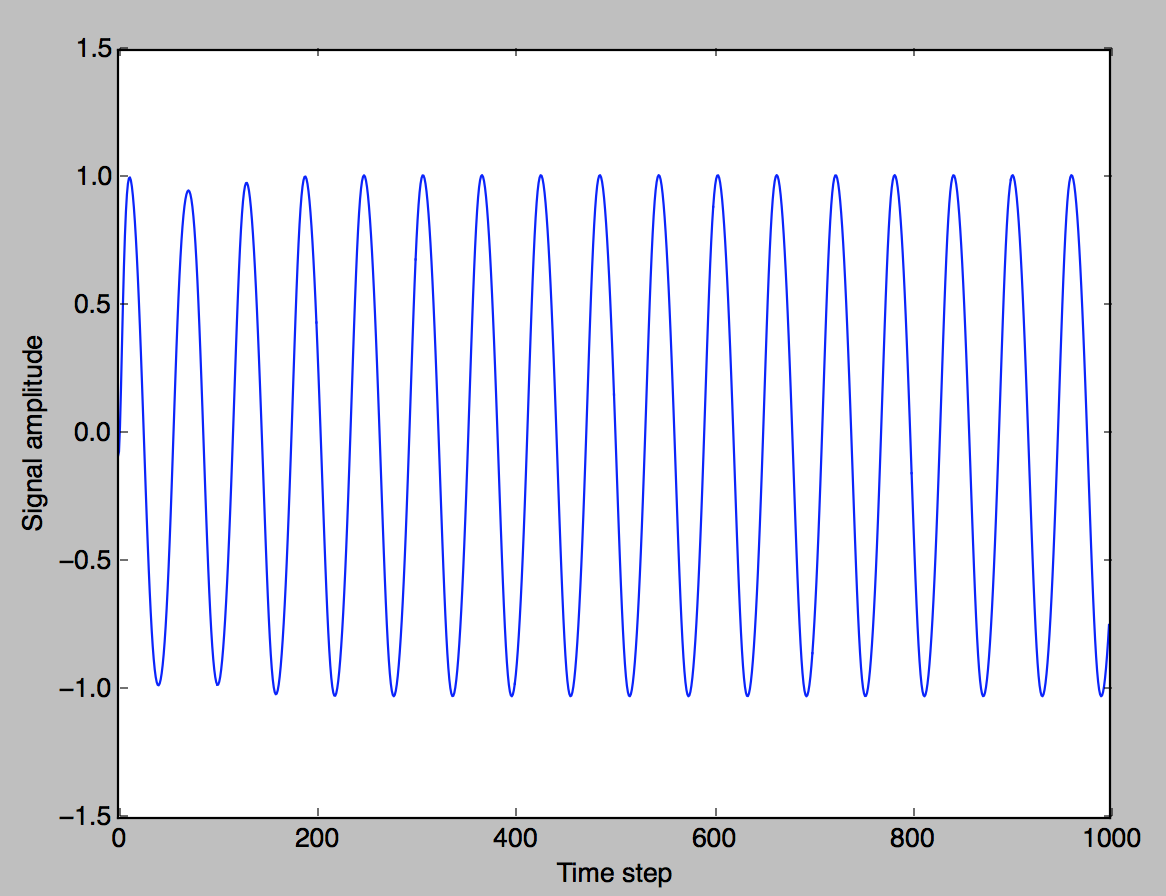
At least with single precision (on cuda) it seems to me that lower loss apparently does not necessarily mean nicer looking predictions (at ~1e-4), I find both.
I would expect something to be up regarding single precision given that the example is done with doubles…
It seems that after switching from LBFGS to Adam also converges similarly.
I have not been entirely successful using double precision on cuda.
Is that similar to your experiences? What’s the conclusion, in particular for the first point.