> import pandas as pd
> import torch
> from torch.autograd import Variable
> import torch.nn as nn
> import numpy as np
> import matplotlib.pyplot as plt
> from itertools import chain
> import numpy.random as random
> import torch.optim as optim
> USE_CUDA=False
> FloatTensor=torch.cuda.FloatTensor if USE_CUDA else torch.FloatTensor
> LongTensor=torch.cuda.LongTensor if USE_CUDA else torch.LongTensor
>
> pi=3.1415926
> flatten = lambda l: [item for sublist in l for item in sublist]
> A=[[np.sin(2*pi/5*x),1] for x in range(-50,50,1)]
> B=[[np.cos(2*pi/10*x),0] for x in range(-50,50,1)]
> def sp(A,lens):
> number=int(len(A)/lens)
> X=A[:number*lens]
> te=[A[i*lens:(i+1)*lens] for i in range(number)]
> return te
> Seq=10
> C=sp(A,Seq)+sp(B,Seq)
> random.seed(1024)
> random.shuffle(C)
> C=list(flatten(C))
> X=np.array(C)[:,0]
> Y=np.array(C)[:,1]
>
> batch_size=20;
> seq_len=10;#sequence length to predict the label of the sequence
> embed_size=1;
> y_size=2;
> def resize(X,Y,batch_size,seq_len,embed_size=1):#divide data into "num" parts.The dimension of each part is Batch_size*Seq_len*Embed_size
> num=int(len(X)/(batch_size*seq_len));
> X=np.array(X)
> Y=np.array(Y)
> i=0;
> X0=X[:num*batch_size*seq_len]
> Y0=Y[:num*batch_size*seq_len]
> t1=X0.reshape(-1,batch_size,seq_len,1)
> t2=Y0.reshape(-1,batch_size,seq_len,1)
> while i<num:
> yield t1[i],t2[i]
> i=i+1
> data=resize(X,Y,batch_size,seq_len)
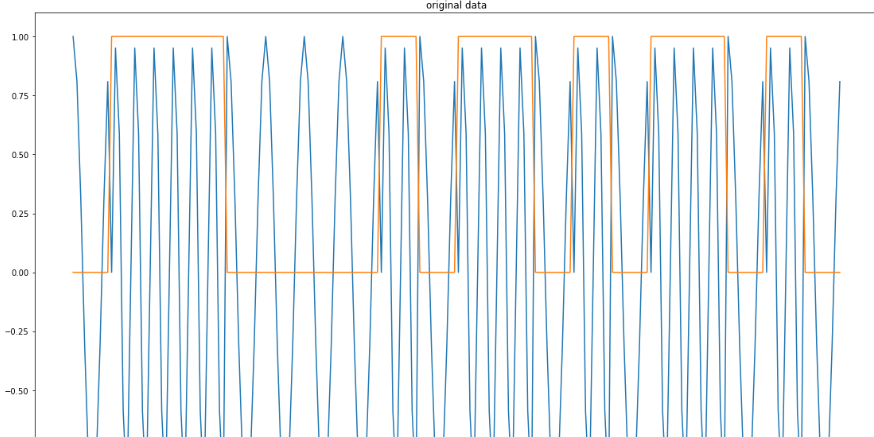
> plt.figure(figsize=(19, 12))
> tt=range(len(X))
> plt.plot(tt,X,tt,Y)
> plt.show()
> class net(nn.Module):
> def __init__(self,batch_size,embed_size,hidden_size,y_size,num_layers=1):
> super(net,self).__init__()
> self.batch_size=batch_size;
> self.num_layers=num_layers;
> self.hidden_size=hidden_size;
> self.embed_size=embed_size;
> self.lstm=nn.LSTM(embed_size,hidden_size,num_layers,batch_first=True)
> self.linear=nn.Linear(hidden_size,y_size)
> self.fun=nn.ReLU()
> self.soft=nn.Softmax()
> def forward(self,inputs,hidden):
> out,hidden=self.lstm(inputs,hidden)#inputs'dimension is Batch*Seq*Embed, hidden's #dimension is 1*Batch*hidden_size
> #out's dimesion is Seq*Batch*hidden_size
> x=out.contiguous().view(-1,out.size(2))#x's dimesion is (Seq*Batch)*hidden_size
> temp=self.linear(x)#temp's dimesion is (Seq*Batch)*y_size
> temp=self.fun(temp)
> z=self.soft(temp)
> return z,hidden#z's dimesion is (Batch*Seq)*y_size
> def init__weight(self):
> self.linear.weight=nn.init.xavier_uniform(self.linear.weight)
> self.linear.bias.data.fill_(0)
> def init__hidden(self,batch_size):
> hidden=Variable(torch.zeros(self.num_layers,self.batch_size,self.hidden_size))
> c=Variable(torch.zeros(self.num_layers,self.batch_size,self.hidden_size))
> return hidden,c
> def hidden_detach(self,hiddens):
> hidden=tuple([hidden.detach() for hidden in hiddens])
> return hidden
> data=resize(X,Y,batch_size,seq_len,embed_size)
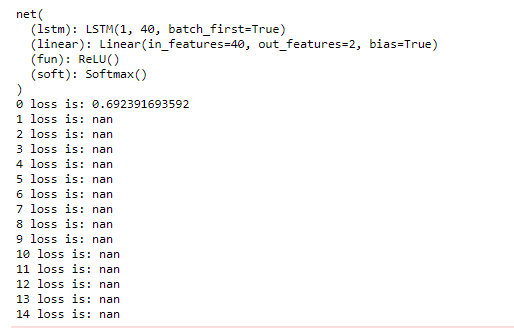
> mynet=net(batch_size,embed_size,40,y_size,1)
> print(mynet)
> optim_=torch.optim.Adam(mynet.parameters(),lr=0.0001)
> loss_=nn.CrossEntropyLoss()
> for epoch in range(15):
> hidden=mynet.init__hidden(batch_size)
> mynet.init__weight()
> losses=[]
> for i,data_ in enumerate(data):
> x,y=data_;
> hidden=mynet.hidden_detach(hidden)
> x=Variable(FloatTensor(x))#x's dimesion is Batch*Seq*Embed
> y=Variable(LongTensor(y))#y's dimesion is Bacth*Seq*1
> optim_.zero_grad()
> pred,hidden=mynet(x,hidden)
> #yt=yt.view(-1)
> pred=pred.view(seq_len,batch_size,-1)[-1]
> target=y.view(batch_size,-1)[:,-1]
> loss=loss_(pred,target)
> losses.append(loss.data.tolist()[0])
> torch.nn.utils.clip_grad_norm(mynet.parameters(), 0.05) # gradient clipping
> loss.backward()
> optim_.step()
> print(epoch,"loss is:",np.mean(losses))