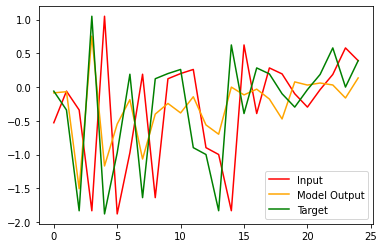
I am creating a model for music generation, but my proble is that for some reason modelpredicts a current step, and not a next step as a label says, even though i compute loss between model output and labels, and labels are shifted by 1 forward:
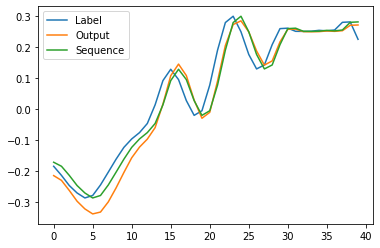
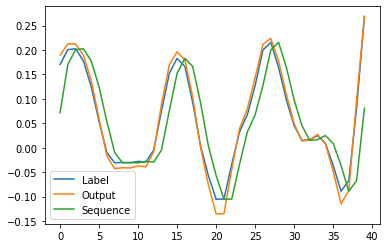
Sequence - model input
Label - sequence shifted 1 step forward
Output - model output
And if i feed in the label as input, it “predicts” the label, so model is basically repeating the input
Dataset code:
class h5FileDataset(Dataset):
def __init__(self, h5dir, seq_length):
self.h5dir = h5dir
self.seq_length = seq_length + 1
with h5py.File(h5dir,'r') as datafile:
self.length = len(datafile['audio']) // self.seq_length
def __len__(self):
return self.length
def __getitem__(self,idx):
with h5py.File(self.h5dir,'r') as datafile:
seq = datafile["audio"][idx*self.seq_length:idx*self.seq_length+self.seq_length]
feature = seq[0:len(seq)-1].astype('float32') #from 0 to second-to last element
label = seq[1:len(seq)].astype('float32') #from 1 to last element
return feature,label
Model code:
class old_network(nn.Module):
def __init__(self, input_size=1, hidden_layer_size=1, output_size=1, seq_length_ = 1, batch_size_ = 128):
super().__init__()
self.hidden_layer_size = hidden_layer_size
self.batch_size = batch_size_
self.seq_length = seq_length_
self.lstm = nn.LSTM(input_size, hidden_layer_size, batch_first = False, num_layers = 2)
self.linear1 = nn.Linear(hidden_layer_size, output_size)
self.linear2 = nn.Linear(hidden_layer_size, output_size)
#self.tanh1 = nn.Tanh()
self.tanh2 = nn.Tanh()
def forward(self, input_seq):
lstm_out, _ = self.lstm(input_seq)
lstm_out = lstm_out.reshape(lstm_out.size(1),lstm_out.size(0),1) #reshape to batch,seq,feature
predictions = self.linear1(lstm_out)
#predictions2 = self.tanh1(predictions1)
predictions = self.linear2(predictions)
predictions = self.tanh2(predictions)
return predictions.reshape(predictions.shape[1],predictions.shape[0],1) #reshape to seq,batch,feature to match labels shape
Training loop:
epochs = 10
batches = len(train_data_loader)
losses = [[],[]]
eval_iter = iter(eval_data_loader)
print("Starting training...")
try:
for epoch in range(epochs):
batch = 1
for seq, labels in train_data_loader:
start = time.time()
seq = seq.reshape(seq_length,batch_size,1).to(DEVICE)
labels = labels.reshape(seq_length,batch_size,1).to(DEVICE)
optimizer.zero_grad()
y_pred = model(seq)
loss = loss_function(y_pred, labels)
loss.backward()
optimizer.step()
try:
eval_seq, eval_labels = next(eval_iter)
except StopIteration:
eval_iter = iter(eval_data_loader)
eval_seq, eval_labels = next(eval_iter)
eval_seq = eval_seq.reshape(seq_length,batch_size,1).to(DEVICE)
eval_labels = eval_labels.reshape(seq_length,batch_size,1).to(DEVICE)
eval_y_pred = model(eval_seq)
eval_loss = loss_function(eval_y_pred, eval_labels)
losses[1].append(eval_loss.item())
losses[0].append(loss.item())
print_inline("Batch {}/{} Time/batch: {:.4f}, Loss: {:.4f} Loss_eval: {:.4f}".format(batch,batches,time.time()-start, loss.item(), eval_loss.item()))
batch += 1
if batch%50 == 0:
print("\n Epoch: {}/{} Batch:{} Loss_train:{:.4f} Loss_eval: {:.4f}".format(epoch,epochs,batch,loss.item(),eval_loss.item()))
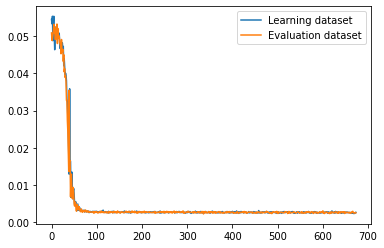
plt.close()
plt.plot(range(0,len(losses[0])),losses[0], label = "Learning dataset")
plt.plot(range(0,len(losses[1])),losses[1], label = "Evaluation dataset")
plt.legend()
plt.show()
torch.save({'model_state_dict':model.state_dict(), 'optimizer_state_dict' : optimizer.state_dict()},save_dir)
except KeyboardInterrupt:
plt.close()
plt.plot(range(0,len(losses[0])),losses[0], label = "Learning dataset")
plt.plot(range(0,len(losses[1])),losses[1], label = "Evaluation dataset")
plt.legend()
plt.show()
I am kinda running out of ideas by this point, not sure what is wrong